6 t検定
「 t検定」は,1つあるいは2つの平均値の検定のためのツールです。jamoviの基本構成では,ここには次の3つの分析メニューが含まれています(図 6.1)。
t検定」は,1つあるいは2つの平均値の検定のためのツールです。jamoviの基本構成では,ここには次の3つの分析メニューが含まれています(図 6.1)。
これらの分析メニューでは,平均値の検定だけでなく,それぞれに対応したノンパラメトリック検定を行うこともできます。また,本書では詳しくは取り上げませんが,ベイズ統計の考え方を用いた指標を算出することも可能です。
6.1 対応なしt検定
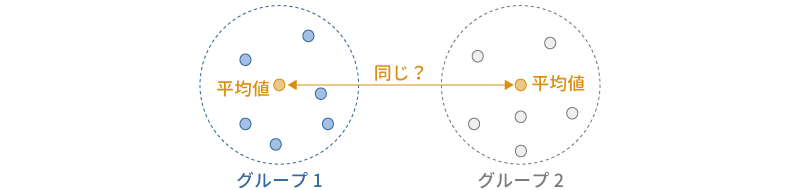
対応なしt検定(独立標本t検定)は,お互いに関連のない(独立な)2つのグループの間で母集団の平均値に統計的な差があるといえるかどうかを確かめたい場合に使用される分析手法です(図 6.2)。
6.1.1 考え方
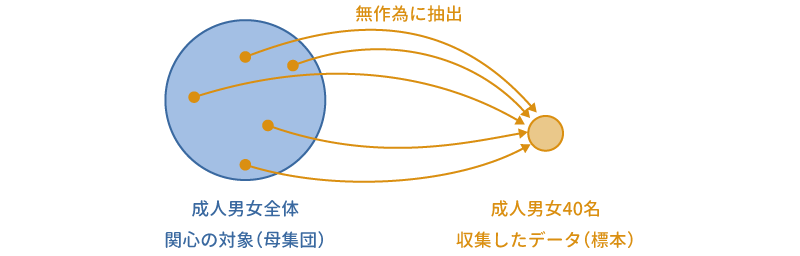
統計的仮説検定は,推測統計と呼ばれる統計手法を応用したもので,手元にあるデータは関心の対象である集団全体(母集団)から無作為抽出された一部(標本,サンプル)であるとみなします(図 6.3)。
推測統計の詳細については統計法の入門書を参照していただきたいと思いますが,母集団からその一部を標本として無作為抽出したとき,その標本がもつ値(平均値や分散など)は母集団のもつ値(母平均や母分散など)とは必ずしも一致しません。母集団の中から無作為に標本を抽出するということは,標本抽出のたびにそこからとり出される値が異なるということですから,同じ母集団から抽出された標本であっても,その平均値や分散は標本ごとにいくらか異なる値になるためです。
もちろん,標本ごとに平均値や分散が異なるとはいえ,まったくでたらめに異なるわけではなく,そこには確率的な法則性が存在します。たとえば,平均値0,分散1で正規分布する母集団から無作為抽出された標本の平均値は0に近い値になる場合がほとんどで,10や\(-\textsf{8}\)といった値になることは確率的にごくまれです。統計的仮説検定では,こうした母集団と標本の間の確率的な関係を利用しながら,母集団の特徴について判断を行うのです。
対応なしt検定では,「両母集団の平均値は同じである(母集団間の平均値の差は0である)」という仮説(帰無仮説)についての検討を行います。もし2つの母集団(2つのグループ)の平均値が同じであるならば,そこからそれぞれ別々に抽出された標本の平均値もほぼ同じ値になるはずです。にもかかわらず,2グループの標本の平均値が大きく異なっていたとしたら,それは「両母集団の平均値は同じ」という仮説自体に無理があるということになるでしょう。
このような考え方に基づいて,対応なしt検定では,2標本の平均値の差が帰無仮説のもとではあり得ないほど大きなものである場合に帰無仮説を棄却します。このとき,この「あり得なさ」の判断基準となるのが有意確率(p)です。このp値は,「帰無仮説が正しい」場合に手元の標本における平均値の差と同じかそれより大きな差が得られる確率を示しており,この値が有意水準 α(一般には0.05)より小さい場合に,帰無仮説が正しくない(つまり2グループの平均値に有意差がある)と判断します。
6.1.2 分析手順
ここでは次のサンプルデータ(ttests_data01.omv)を用いて対応なしt検定の実施方法について見ていきましょう。このデータに含まれている変数は次のとおりです(図 6.4)。データファイルには,グループ1とグループ2のそれぞれ20名ずつ,計40名の課題得点データが含まれています。
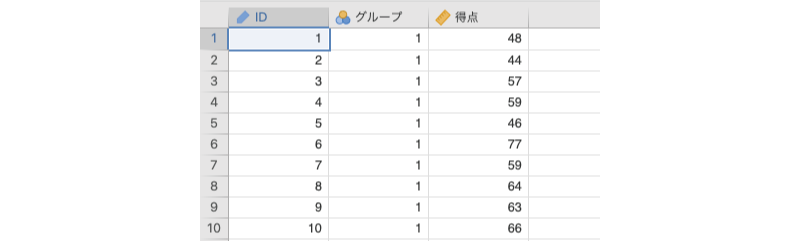
ID対象者のIDグループ対象者のグループ(1または2)得点対象者の課題得点
それでは,グループ1とグループ2で,課題得点の平均値に差があるといえるかどうかを検定してみましょう。対応なしt検定を行うには,分析タブの「 t検定」から「対応なしt検定」を選択します(図 6.5)。
すると,図 6.6のような画面が表示されます。設定項目がたくさんあるので,まずは全体的な構成を見ておきましょう。
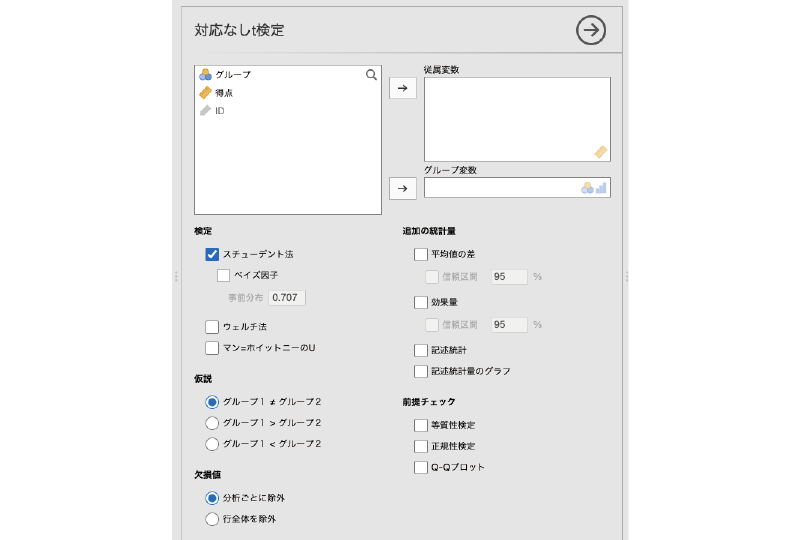
- 従属変数 分析対象の変数を指定します。
- グループ変数 グループの別が入力されている変数を指定します。
- 検定 分析に用いる検定のタイプを指定します。
- 仮説 検定に用いる仮説を選択します。
- 欠損値 データに欠損値が含まれている場合の対処方法を指定します。
- 追加の統計量 一般的な分析結果に加えて算出したい統計量を指定します。
- 前提チェック 検定に必要な前提条件が満たされているかどうかの確認を行います。
この分析で必ず設定する必要がある項目は「従属変数」と「グループ変数」の2つです。従属変数は検定対象になる平均値を算出する変数(サンプルデータでは「得点」),グループ変数は比較したいグループの分類基準となる変数(サンプルデータでは「グループ」)です。2つのグループの平均値の差について検定するわけですから,「グループ」と「得点」の指定が必要なのは当然でしょう。
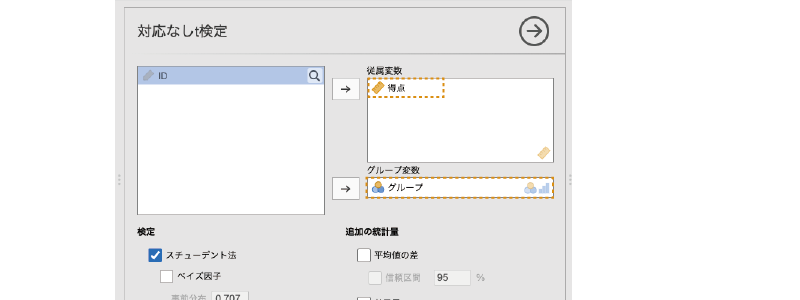
この2つを設定すると,すぐにそれが分析結果に反映されます(図 6.8)。

結果の表の一番左(「得点」)は従属変数の名前,左から2番目は検定方法の名前です。対応なしt検定にはスチューデントの検定とウェルチの検定と呼ばれる2とおりの方法があり,ここに「スチューデントのt」と示されていれば,それはスチューデントの検定の結果であるということを示しています。
その隣の「統計量」の列は検定統計量(ここではスチューデントのt),その隣は「自由度」,「p」は有意確率(p値)です。このpが有意水準(一般にはα=0.05)より小さい場合に「差が有意」と判断します。ここで表示されている結果ではp=0.024ですから,グループ1と2の平均値の間には統計的に有意な差があるということになります。
さて,ほとんどの場合,これで「対応なしt検定」はおしまいです。拍子抜けするくらいに簡単ですね。
6.1.3 分析の詳細設定
先ほど見たように,jamoviを用いたt検定では設定らしい設定が不要で,分析の実行は驚くほど簡単なのですが,場合によっては分析設定の変更が必要になる場合があるかもしれません。そこで,ここでは対応なしt検定における設定の詳細について見ておくことにしましょう。
検定
「検定」には,次の項目が含まれています(図 6.9)。ここでは,t検定における検定統計量の算出方法について設定を行います。
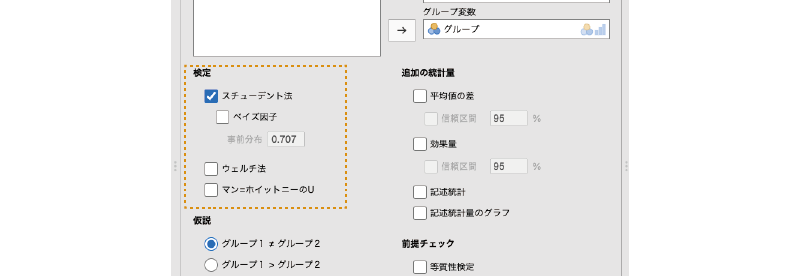
- スチューデント法 スチューデントの検定による検定結果を表示します。
- ベイズ因子 帰無仮説と対立仮説の間でベイズ因子を算出します。
- ウェルチ法 ウェルチの検定による検定結果を表示します。
- マン=ホイットニーのU マン=ホイットニーのU検定の結果を表示します。
スチューデント法
この項目がチェックされている場合,スチューデントのt検定を用いた検定結果が表示されます。スチューデントのt検定では,平均値の差について検討する2つの母集団は平均値だけでなく分散も等しいという仮定のもとで検定統計量を算出します。そのため,一般には「2つの母集団で分散が等しい」という仮定から大きく逸脱しないデータで検定する際の方法として使用されています。
この項目に含まれる「ベイズ因子」は,ベイズ統計の考え方を用いて仮説検定をする際に用いられる値です。この値は,対立仮説の確からしさと帰無仮説の確からしさを比で表したもので,この値が1の場合には帰無仮説と対立仮説の確からしさが同じであることを,1未満の場合には帰無仮説の方が,1より大きい場合には対立仮説の方が確からしいことを意味します。一般には,このベイズ因子の値が3.0以上である場合に,帰無仮説を棄却して対立仮説を採択します1。
このベイズ因子の項目にある「事前分布」はベイズ因子の算出に使用されるもので,これは事前分布に関する設定値です。この値は初期値では「\(\sqrt{2}/2=0.707\)」に設定されています。ベイズ因子の算出にチェックを入れた場合,ベイズ因子の隣にその推定誤差(±%)も表示されます。
ウェルチ法
スチューデントの検定では2つの母集団で分散が等しいという仮定を用いて検定統計量を算出しますが,ウェルチのt検定ではそうした前提を設けずに検定統計量を算出します。そのため,一般にこの方法は2つの母集団で分散が異なっている場合に用いられます。
ウェルチの検定の項目にチェックを入れた場合,結果の表では「ウェルチのt」の行にその分析結果が表示されます。ウェルチの検定では,多くの場合,自由度が整数でなく,小数値を含んだものになります。
マン=ホイットニーのU
t検定は母集団の分布が正規分布であるという前提のもとで計算を行います。しかし実際のデータでは,このような前提が成り立たない場合,あるいは成り立つかどうかが不明な場合というのもあり得ます。
これに対し,マン=ホイットニーのU検定は,母集団の分布の形に特別な仮定を設けずに検定を行うため,正規分布でないようなデータであっても分析が可能になります。このような方法は,ノンパラメトリック検定と呼ばれます。
「マン=ホイットニーのU」にチェックを入れた場合,その結果は「マン=ホイットニーのU」の行に表示されます。
仮説
「仮説」には,次の項目が含まれています(図 6.10)。

- グループ1 ≠ グループ2 グループ1とグループ2で平均値が異なるかどうかを検定します(両側検定)
- グループ1 > グループ2 グループ1の平均値がグループ2の平均値より大きいかどうかを検定します(片側検定)
- グループ1 < グループ2 グループ1の平均値がグループ2の平均値より小さいかどうかを検定します(片側検定)
ここでは検定に使用する対立仮説の設定を行います。一般に,t検定における対立仮説には「グループ1 ≠ グループ2」が用いられます。この対立仮説は,2つのグループで平均値が異なるということのみを示しており,グループ1とグループ2のどちらの平均値が大きいかまでは述べていません。この場合,グループ1の平均値がグループ2の平均値より大きくても小さくても検定結果が有意になります。このような検定方法は両側検定と呼ばれます。
これに対し,「グループ1 > グループ2」はグループ1の平均値がグループ2より大きい場合のみ,「グループ1 < グループ2」はグループ1の平均値がグループ2より小さい場合のみ検定結果が有意になります。このように,一方のグループの平均値がもう一方よりも大きいかどうかのみ,あるいは小さいかどうかのみを確かめる検定方法は片側検定と呼ばれます。
欠損値
「欠損値」には,次の項目が含まれています(図 6.11)。

- 分析ごとに除外
- 行全体を除外
ここでは,データに欠損値があった場合にどう対処するかについての設定を行います。この設定は,同時に複数の変数について平均値の検定を行う場合にのみ影響します。
分析ごとに除外
ここで「分析ごとに除外」を選択した場合,それぞれの検定において欠損値を分析から除外します。2種類の変数XとYについてグループ1とグループ2で平均値に差があるかどうかを検定している場合で,ある対象者のXの値が欠落している場合,Xの平均値の検定においてはその対象者のデータは分析から除外されますが,Yの平均値の検定でその対象者のデータが分析から除外されることはありません。
行全体を除外
これに対し,「行全体を除外」を選択した場合には,XまたはYのいずれかの値が欠落している対象者のデータは,XとYの両方の検定で分析から除外されます。
追加の統計量
「追加の統計量」には,次の項目が含まれています(図 6.12)。
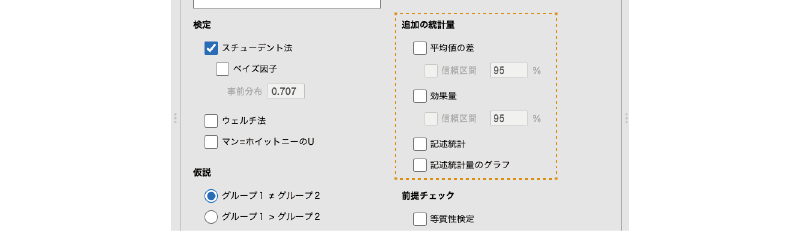
- 平均値の差 グループ間の平均値の差とその標準誤差を算出します。
- 信頼区間 平均値の差の信頼区間を算出します。
- 効果量 平均値の差についての効果量を算出します。
- 信頼区間 効果量の信頼区間を算出します。
- 記述統計 従属変数について,グループごとの記述統計量を算出します。
- 記述統計量のグラフ 従属変数の平均値と中央値についてのグラフを作成します。
平均値の差
「平均値の差」にチェックを入れると,2グループ間の平均値の差の値と,その標準誤差が表示されます。なお,t検定の検定統計量(t)は,この「グループ間の平均値の差」を標準誤差で割ることによって算出されます。
その下にある「信頼区間」にチェックを入れると,平均値の差の信頼区間(下限および上限)が算出されます。信頼区間の幅は初期設定では95%になっていますが,数値を変更すれば99%信頼区間などを算出することも可能です。
効果量
「効果量」にチェックを入れると,平均値の差についての効果量が算出されます。また,その下にある「信頼区間」にチェックを入れると,その効果量についての信頼区間が算出できます。なお,t検定に対する効果量としては「コーエンのd(Cohen’s d)」が,マン=ホイットニーのU検定に対する効果量としては「順位双列相関係数」が算出されます。
平均値の検定で検定統計量として用いられるtは,「差の大きさ」を表す値ではありません。この値は平均値の差を標準誤差で割って求められますが,標準誤差は標本サイズが大きくなるほど小さくなるため,標本サイズの大きなデータを対象とした検定では,平均値の差が実質的に無意味なほど小さなものであっても結果が有意になる場合があるのです。
これに対し,コーエンのdという統計量は,平均値の差が標準偏差の何倍の大きさであるかを示した値です。標準誤差と違い,標準偏差は標本サイズの大小によって極端に変わるようなことがありません。そのため,どのような標本データに対しても「差の大きさ」を安定的に評価できるのです。このdの値(の絶対値)が大きいほど,平均値の差が大きいことを意味します。コーエンのdの大きさの解釈については,一般に表 6.1のような目安が用いられています。APAの論文執筆マニュアル第7版や日本心理学会の論文執筆・投稿の手びきに見られるように,近年では分析結果で効果量を示すよう求められることが多くなってきています。
| dの値 | 効果の大きさ |
|---|---|
| 0.8 | 大 |
| 0.5 | 中 |
| 0.2 | 小 |
なお,マン=ホイットニーのU検定の場合には効果量として順位双列相関係数という値が算出されます。これは,順序データと2値データの間の相関係数です。順位双列相関係数の解釈の仕方は,基本的にはピアソンの積率相関係数と同様です。
記述統計
「追加の統計量」にある「記述統計」にチェックを入れると,分析対象の変数(従属変数)について,グループごとの平均値や標準偏差などの記述統計量が算出されます(図 6.13)。

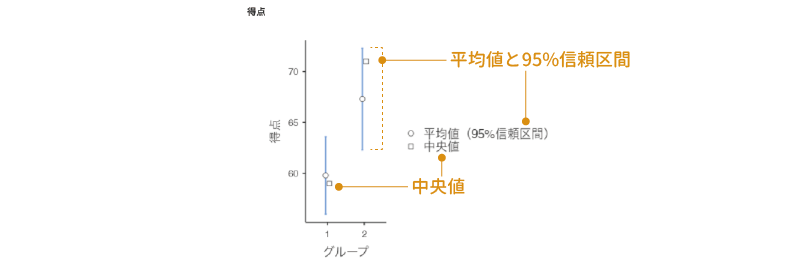
記述統計量のグラフ
また,その下の「記述統計量のグラフ」にチェックを入れると,グループごとの平均値および中央値が図 6.14のようなグラフで示されます。
前提チェック
「前提チェック」には,次の項目が含まれています(図 6.15)。

- 等質性検定 分散の等質性についての検定を実施します。
- 正規性検定 分布の正規性についての検定を実施します。
- Q-Qプロット 正規Q-Qプロットを作成します。
対応なしt検定では,分析対象となる母集団の分布についていくつかの仮定(前提)を設けることによって計算を効率化しているため,それらの前提を満たしていないデータに対しては分析結果の信頼性が低くなります。t検定の前提条件についての詳細は統計法の教科書などを参照してもらうこととして,ここではそれらのうち,jamoviの設定項目と関連する2つの前提について見ておきます。
等質性検定
まず,1つ目の「等質性検定」ですが,これは2つのグループで分散が等しいかどうかについて確かめるものです。スチューデントの検定では,2つのグループで分散が等しいことを前提として検定統計量を算出します。そのため,2グループの分散が極端に異なる場合には,正確な検定結果を得ることができません。そこで,2つのグループで分散が極端に異ならないかどうかを検定するのがこの設定項目です。
この「等質性検定」にチェックを入れると,図 6.16のような形でルビーン検定と呼ばれる分散の等質性検定の結果が表示されます。

この表の「F」の値は,2つのグループにおける分散の比で,この値が1であれば2グループの分散が等しいことを,1より極端に大きければ,2グループで分散が大きく異なることを意味します。一般には,このFについての有意確率(p)が0.05未満,または0.10未満の場合に2つのグループで分散が異なると判断します。この検定の結果が有意であった場合,スチューデントの検定の前提条件が満たされないことになりますので,その場合にはウェルチの検定を用いることになります。
正規性検定
前提チェックの2つ目の項目である「正規性検定」は,分析対象のデータが正規分布からかけ離れていないかどうかを確かめるものです。対応なしt検定では,データの母集団が正規分布であることを前提としていますので,この前提が満たされない場合には,母集団に正規分布を仮定しないマン=ホイットニーのUなどのノンパラメトリックな手法を用いる必要があります。
そこでjamoviでは,シャピロ=ウィルク検定(Shapiro-Wilk検定)と呼ばれる手法を用いて正規性の検定を行います。この検定は,「標本データは正規分布する母集団から無作為抽出されたものである」という帰無仮説について検定を行います。一般に,この分析結果のp値が0.05未満の場合に,データの母集団が正規分布でないとみなします(図 6.17)。

Q-Qプロット
前提チェックの3つ目の項目である「Q-Qプロット」は,標本データが正規分布からかけ離れていないかどうかを視覚的に確認するための手法です。正規分布する母集団から無作為抽出された標本は,母集団と同じく正規分布になるという数学的な性質がありますので,標本データが正規分布からかけ離れている場合には,母集団の分布も正規分布でない可能性が高まります。
「Q-Qプロット」の項目にチェックを入れると,出力ウィンドウに次のようなグラフが表示されます。このQ-Qプロットと呼ばれる図では,横軸に理論的な分位数,縦軸に標準化残差をとって,各測定値をグラフ上にプロットします。このとき,データが正規分布している場合には,すべての測定値は直線上に並ぶことになります。そのため,このQ-Qプロットで各測定値を示す点が直線から極端に離れていなければ,標本データはほぼ正規分布しているということになり,その母集団も正規分布である可能性が高まります。
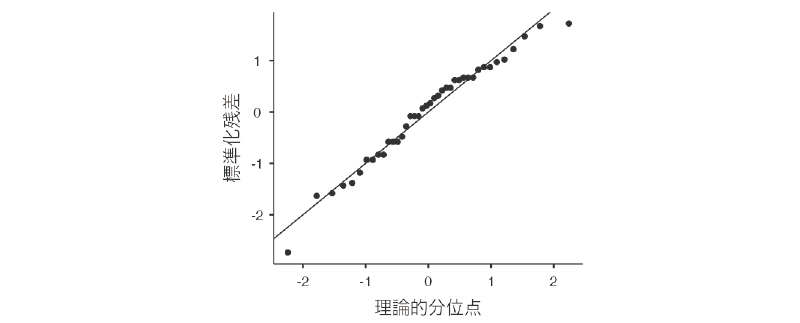
例題データの場合,両端のデータ点が直線からやや外れた位置にありますが,それ以外はほぼ直線上にあるので,正規分布から極端に離れていることはなさそうです。
6.2 対応ありt検定
今度は対応ありt検定について見ていきましょう。対応ありt検定は,2種類の測定値の間に明確なペアが存在する場合に,その母集団の平均値に統計的な差があるといえるかどうかを確かめるのに使用されます(図 6.19)。
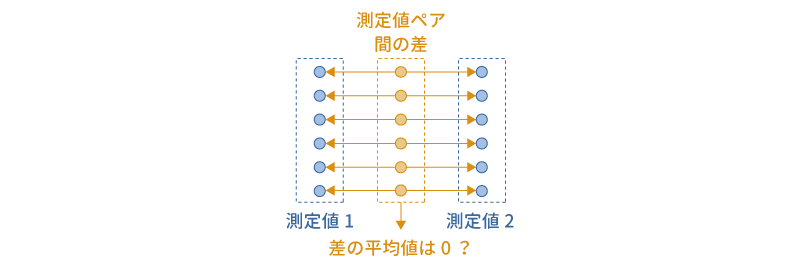
この検定が用いられる典型的な場面は,ある処置を行う前後で平均値に差があるかどうかを確かめるというものです。この場合,それぞれの対象者について処置前と処置後の2回の測定を行いますので,同じ対象者の測定値同士で前後の比較を行うことができます。このように,2つのグループ(処置前と処置後)の測定値の間で特定のペアが成立するデータを一般に「対応ありデータ」と呼びます。
6.2.1 考え方
対応なしt検定の場合と異なり,対応ありt検定では対象者ごとに2つの条件における測定値の差を求め,その「測定値の差の平均値」を用いて検定を行います。2つの条件(処置前と処置後など)に違いがなければ,どちらの条件の測定値も同じような値になるはずで,その場合,2条件の測定値の差の平均値は0に近い値になります。このような考えから,対応ありt検定では,2条件の測定値の差の平均値が0であるといえるかどうかを確かめます。
6.2.2 分析手順
ここでは次のサンプルデータ(ttests_data02.omv)を用いて対応ありt検定の実施方法を見ていきましょう。このデータは,20名の参加者を対象に,効率的な記憶法の訓練前と訓練後における記憶課題の成績を測定したものです。このデータファイルには,次の3つの変数値が格納されています(図 6.20)。
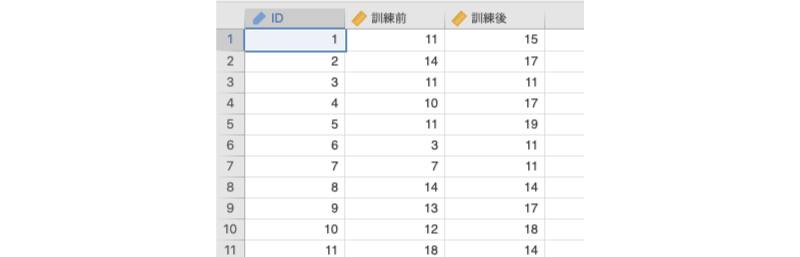
ID対象者のID訓練前訓練前の記憶課題成績訓練後訓練後の記憶課題成績
それでは,訓練前と訓練後で,記憶課題成績の平均値に差があるといえるかどうかを検定してみましょう。対応ありt検定を行うには,分析タブの「 t検定」から「対応ありt検定」を選択します(図 6.21)。
すると,図 6.22のような画面が表示されます。設定項目がたくさんありますが,そのほとんどは対応なしt検定の場合と同じです。
- 変数ペア 分析対象の変数ペアを指定します
- 検定 分析に用いる検定を指定します
- 仮説 検定に用いる仮説を選択します
- 欠損値 データに欠損値が含まれている場合の対処方法を指定します
- 追加の統計量 一般的な分析結果に加えて算出したい統計量を指定します
- 前提チェック 検定に必要な前提条件が満たされているかどうかの確認を行います
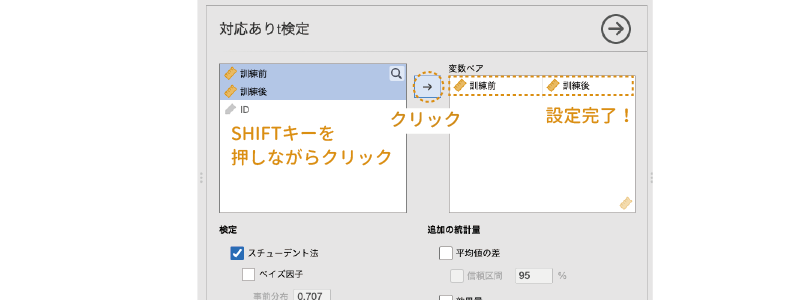
この分析で必ず設定する必要がある項目は「変数ペア」のみです。変数ペアには,分析対象となる変数のペアを指定します。サンプルデータの場合,「訓練前」と「訓練後」の差について検定したいので,この2つを「変数ペア」欄に移動します。
このとき,「訓練前」と「訓練後」を1つずつ「変数ペア」欄に移動することもできますが,2つまとめて移動させる方がわかりやすいでしょう。まずどちらか一方の変数名をクリックして選択した後,「SHIFT(⇧)」キーを押しながらもう一方の変数名をクリックすると2つの変数を同時に選択することができますので,その状態で「 」をクリックして変数ペアの設定を行います(図 6.23)。
」をクリックして変数ペアの設定を行います(図 6.23)。
対応なしt検定の場合と同様に,この設定だけで基本的な分析結果が得られます(図 6.24)。

変数名の代わりに変数ペアが表示されること以外は,分析結果の表も対応なしt検定の場合と同じです。この分析結果では,有意確率pの値が「<.001(0.001未満)」となっていますので,検定結果は有意,つまり記憶法の訓練前後で平均値に有意な差があるということになります。
なお,検定統計量は変数ペアの左側の変数から右側の変数の値を引いて算出されています(サンプルデータの場合は「訓練前 − 訓練後」)。両側検定の場合,検定結果が有意かどうかは統計量の絶対値で判断しますので問題ありませんが,片側検定の場合,この統計量がどちらからどちらを引いた値に基づくものであるのかに注意が必要になります。
この分析の設定項目は,「検定」の部分を除いて対応なしt検定の場合と同じです。重複する部分については説明を省略します。
検定
対応ありt検定の「検定」には,次の項目が含まれています(図 6.25)。
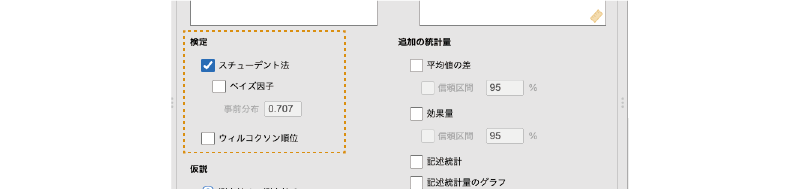
- スチューデント法 スチューデントの検定による検定結果を表示します。
- ベイズ因子 帰無仮説と対立仮説の間でベイズ因子を算出します。
- ウィルコクソン符号順位検定 ウィルコクソン符号順位検定(Wilcoxon符号順位検定)の結果を表示します。
「検定」の項目もほとんどは対応なしt検定の場合と同じですが,対応ありt検定の場合,t検定の計算方法はスチューデントの検定のみになります。また,この場合のノンパラメトリック検定には,ウィルコクソン符号順位検定と呼ばれる検定手法が用いられます。
それ以外の項目は,対応なしt検定の場合とほぼ同じですので,詳細については対応なしt検定のセクションを参照してください。
なお,スチューデントの検定について「追加の統計量」で効果量を算出した場合は,対応なしt検定の場合と同様にコーエンのdが,ウィルコクソン符号順位検定について効果量を算出した場合,マン=ホイットニーの検定の場合と同様に順位双列相関係数が表示されます。
6.3 1標本t検定
最後に1標本のt検定です。1標本t検定は,ある母集団の平均値と特定の値の間に差があるかどうかを確かめたい場合の検定方法です(図 6.26)。
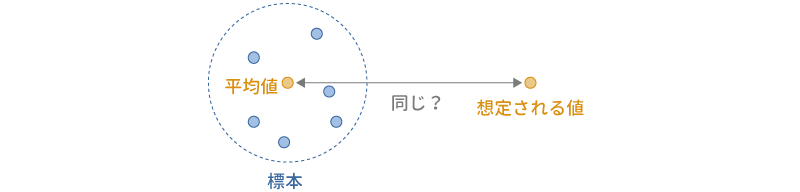
この検定は,あるテストにおける母平均が50点になっているかどうかを確かめたい場合,手元の標本が想定する母集団(平均値100の母集団など)から抽出されたものであるといえるかどうかを確かめたい場合などに用いられます。
6.3.1 考え方
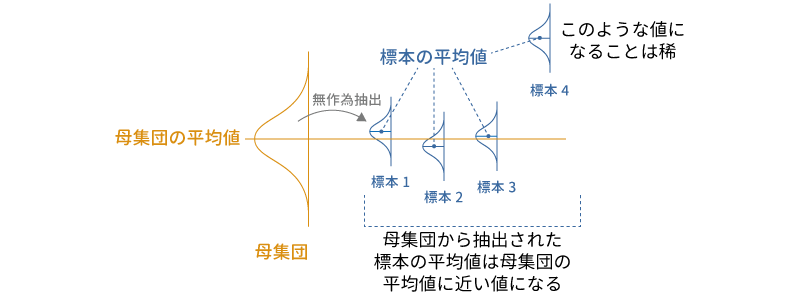
ある母集団から無作為抽出された標本の平均値は,確率的には元の母集団の平均値と同じ値(実際には母集団の平均値周辺の値)になるという性質があります。つまり,平均値が50の母集団から抽出された標本では,その標本の平均値は50,平均値が100の母集団から抽出された標本では,その標本の平均値は100またはその周辺の値になるのです。
この関係を利用して,ある1つの標本について,その母集団の平均値についての検討を行うのがこの1標本t検定です。もし,標本の平均値が51などの値であれば,その標本が平均値50の母集団から抽出されたものである可能性は高いといえるでしょう。しかし,標本の平均値が150の場合,そのような平均値をもつ標本が平均値50の母集団から抽出されたとは考えにくくなります(図 6.27)。
6.3.2 分析手順
ここでは次のサンプルデータ(ttests_data03.omv)を用いて1標本t検定の実施方法を見ていきましょう(図 6.28)。
ID対象者のID得点対象者の課題得点
このデータには,20名の対象者について,ある課題の得点が入力されています。この標本の母集団において,課題得点の平均値が50点であるといえるかどうかを確かめたいとしましょう。
1標本t検定を行うには,分析タブの「 t検定」から「1標本t検定」を選択します(図 6.29)。
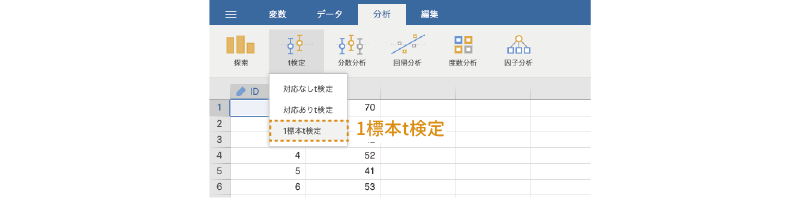
すると,図 6.30のような画面が表示されます。設定項目がたくさんありますが,そのほとんどは対応ありt検定のものと同じです。
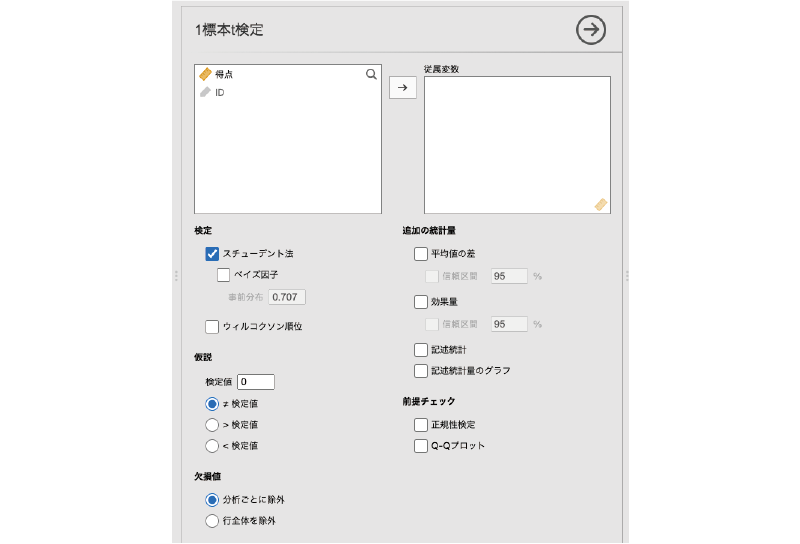
- 従属変数 分析対象の変数を指定します。
- 検定 分析に用いる検定を指定します。
- 仮説 検定に用いる仮説を選択します。
- 欠損値 データに欠損値が含まれている場合の対処方法を指定します。
- 追加の統計量 一般的な分析結果に加えて算出したい統計量を指定します。
- 前提チェック 検定に必要な前提条件が満たされているかどうかの確認を行います。
設定パネルで対応ありt検定と異なっている部分は仮説欄だけです(図 6.31)。
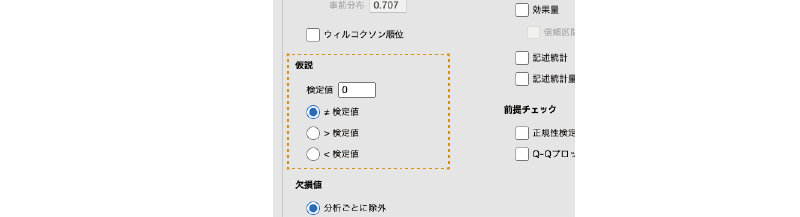
- 検定値 比較したい値を指定します。
- ≠ 検定値 平均値が検定値と異なるかどうかを検定します(両側検定)。
- > 検定値 平均値が検定値より大きいかどうかを検定します(片側検定)。
- < 検定値 平均値が検定値より小さいかどうかを検定します(片側検定)。
では分析の設定を行いましょう。まず,「得点」を「従属変数」に設定します(図 6.32)。
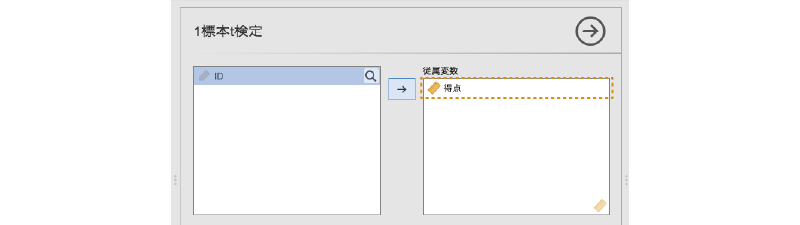
次に,比較対象の値を設定します。今回のサンプルデータでは,平均値が50点といえるかどうかを確かめたいので,「仮説」にある「検定値」の値を50に設定します(図 6.33)。

従属変数と検定値の設定が終わると,出力ウィンドウの結果は図 6.34のようになっているはずです。

表示される結果は対応なしt検定や対応ありt検定の場合とほぼ同じですが,表の下に「H\(_\text{a}\) μ ≠ 50」という検定仮説に関する注釈がつけられている点が異なります。これは,「母集団の平均値が50でない」という対立仮説のもとで検定を行ったことを示しています。1標本t検定では分析者が指定した検定値を用いて検定を行うため,その情報がここに表示されているのです。
この分析結果では,有意確率pが0.002と小さな値ですので,「差が有意(母集団の平均値は50でない)」が分析結果になります。
6.3.3 1標本t検定と対応ありt検定
この1標本t検定は,対応ありt検定と関係が深い分析手法です。対応ありt検定では,2つのグループ間でペアとなる測定値の差を求め,その測定値の差の平均値が0であるかどうかを検定します。このとき,「ペアとなる測定値の差」そのものを一種の測定変数とみなすと,これは「測定値の差」という変数の平均値が0であるかどうかを検定していることになり,1標本t検定とまったく同じになるのです。つまり,対応ありt検定は1標本t検定の特殊ケースなのです。
そのことをここで確かめておきましょう。対応ありt検定のところで使用したサンプルデータ(ttests_data02.omv)を再度開いてください(図 6.35)。
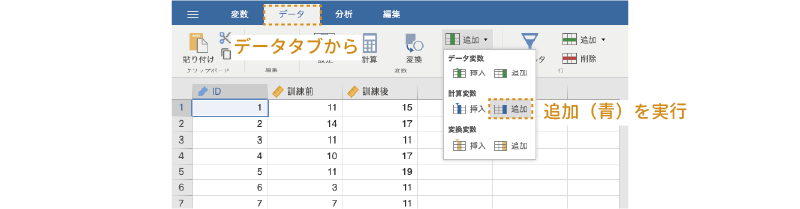
データファイルを開いたら,「変化量」という名前の計算変数を作成し,そこに記憶訓練実施前の得点(「訓練前」)と実施後の得点(「訓練後」)の差を格納しましょう。まず,データタブの「変数」にある「 追加」ボタンから「計算変数」の「
追加」ボタンから「計算変数」の「 追加」を選択して新たに計算変数を追加します(図 6.36)。
追加」を選択して新たに計算変数を追加します(図 6.36)。
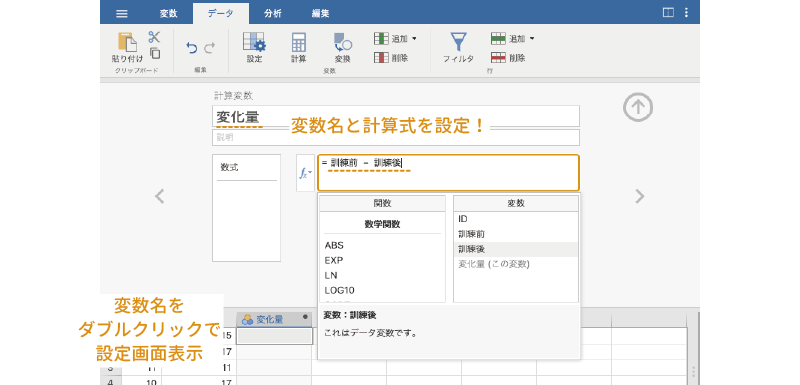
次に,作成した計算変数の変数名の部分「 D」をダブルクリックして,変数設定パネルを表示します。変数名を「変化量」に変更し,計算式の部分に「
D」をダブルクリックして,変数設定パネルを表示します。変数名を「変化量」に変更し,計算式の部分に「訓練前 - 訓練後」と入力してください。マイナス記号(-)を入力する際は,日本語入力がオフになっていることを確認しましょう(図 6.37)。
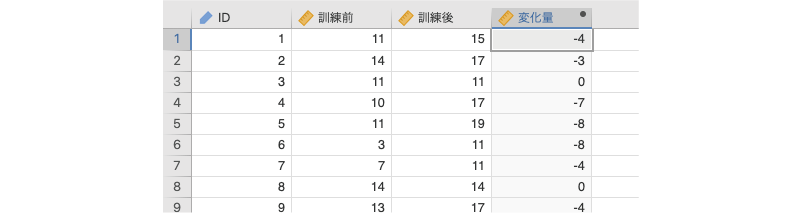
入力を確定して変数設定パネルを閉じると,「訓練前」と「訓練後」の差が「変化量」に入力されていることがわかります(図 6.38)。
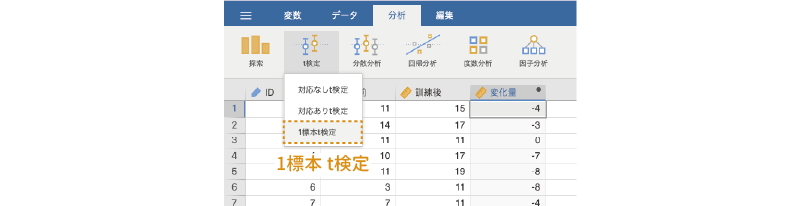
変数の作成が完了したら,分析タブの「 t検定」から「1標本t検定」を選択します(図 6.39 )。
設定パネルで,先ほど作成した「変化量」を従属変数に設定します(図 6.40 )。対応ありt検定では,2グループの差の平均値が0であるかどうかについての検定を行いますので,「仮説」の「検定値」は0のままで構いません。
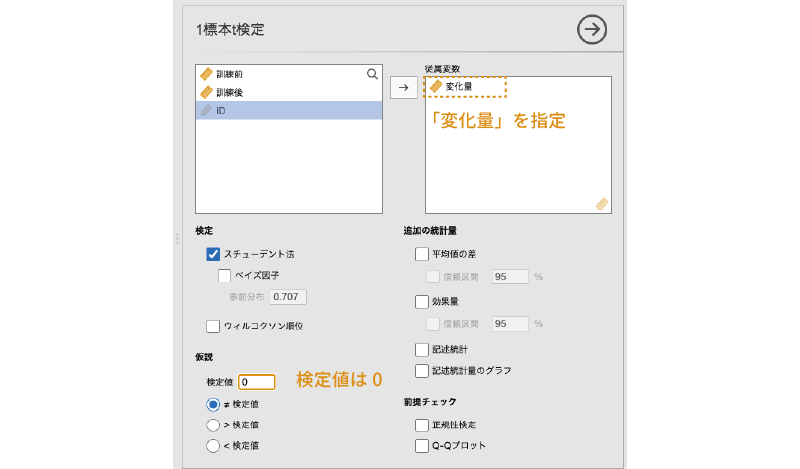
設定が完了すると,分析結果は図 6.41 の「1標本t検定」のようになります。

この結果と,「訓練前」と「訓練後」の間で対応ありt検定を行った場合の結果(対応ありt検定)を見比べてみてください。「変化量」の部分が「訓練前 訓練後」になっていることを除けば,他はすべて同じですね。このように両者で結果が同じになるのは,対応ありt検定が「訓練前」と「訓練後」の差で構成された1標本データについて,その母集団の平均値が0と異なるかどうかを確かめているのと同じことだからなのです。
jamoviのt検定におけるベイズ因子は「対立仮説(H\(_1\)):帰無仮説(H\(_0\))」の比(BF\(_{10}\))の形で示されています。「帰無仮説(H\(_0\)):対立仮説(H\(_1\))」の比(BF\(_{01}\))として示されている場合には,ベイズ因子の値が0に近いほど対立仮説が確からしいことを意味します。↩︎