3 データ操作
本章では,jamoviでのデータ操作の方法について見ていきます。jamoviでのデータの操作はExcelなどの表計算ソフトによく似ていますので,それらに慣れた人であればjamoviでの操作にもすぐ慣れるはずです。また,jamoviではかなり幅広い種類のファイルをデータとして読み込むことができますので,大量のデータを入力する際には,慣れたソフトで入力したものをjamoviで開いて分析するという使い方もできるでしょう。
また,複数の質問への回答を合計あるいは平均して得点を算出するということはExcelのような表計算ソフトでも可能ですが,データに修正が生じた場合などのことを考えると,それらをjamoviでできるようになっておくのがよいでしょう。
この章では,jamoviにおけるそうしたデータ操作の基本について見ていきます。
3.1 画面構成
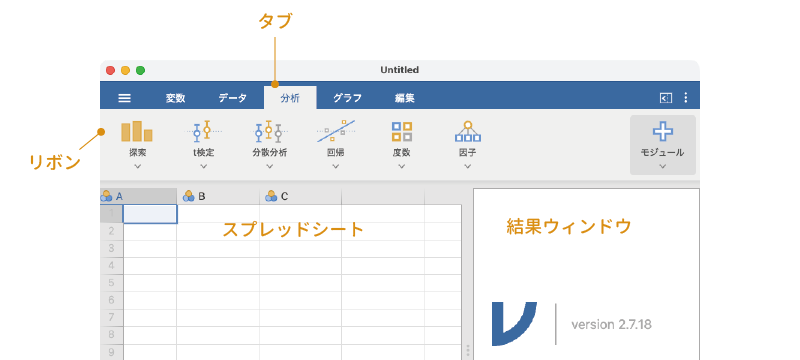
jamoviの画面は,次の要素で構成されています(図 3.1)。
- タブ 使用するリボンを切り替える際に使用します
- リボン jamoviのさまざまな機能にアクセスするためのツール群がここに表示されます
- スプレッドシート データの入力や編集を行う部分です
- 結果ウィンドウ ここに分析結果が表示されます
3.1.1 タブ
jamoviには,「変数」,「データ」,「分析」,「グラフ」,「編集」の5つのタブが用意されています。変数タブはデータファイルに含まれている変数情報の確認に,データタブにはデータ入力に,分析タブはデータ分析の際に使用します。また,グラフタブはデータを可視化したい場合に,編集タブは分析結果にメモを書き込んだりする場合に使用します。
それぞれのタブにどのような項目が用意されているのかを見てみましょう。
変数タブ
変数タブは,次のような画面構成になっています(図 3.2)。
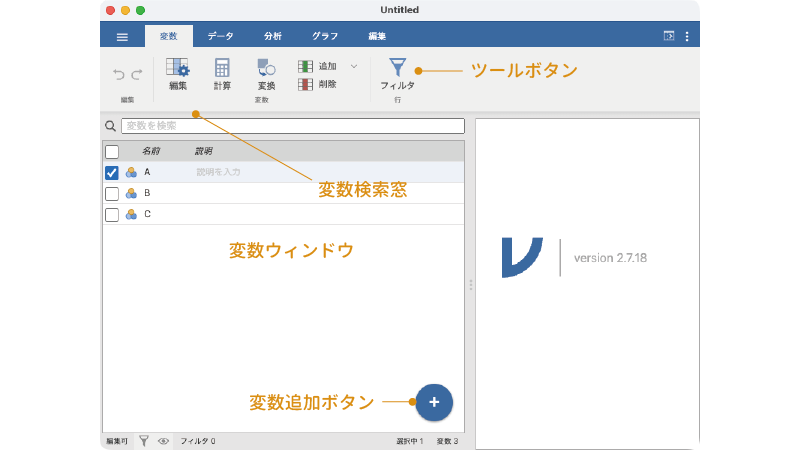
画面上部にはツールボタンのリボンが,中央には変数ウィンドウが,画面下には変数追加ボタンがあります。また,変数の検索窓も用意されており,データにたくさんの変数が含まれている場合にはここに変数名を入力することで目的の変数をすばやく見つけられます。
通常,各変数の変数名はできるだけ簡潔なものにするのが望ましいですが,質問紙データの場合などには,「Q1」や「Q2」などの変数名では,その質問がどのような内容の質問文だったのかの判断が難しくなります。そのような場合,質問文を「説明」欄に入力しておくと,どの変数がどの質問項目のデータなのかを簡単に確認できます。また,jamoviの拡張モジュールでは日本語に対応していないこともありえますし,余分なトラブルを避けるために変数名を英数字のみにしておきたいこともあるでしょう。そのような場合にも,「説明」欄に日本語で各変数の説明をつけておくと,後々の分析が楽になるはずです。
このタブのリボンに含まれているツールボタンは次のとおりです。
- 編集 操作の取り消し(
 ),やり直し(
),やり直し( )を行います。
)を行います。  編集 データ変数の設定を行います。
編集 データ変数の設定を行います。 計算 すでにある変数値から新たな変数を作成します。
計算 すでにある変数値から新たな変数を作成します。 変換 すでにある変数値に変換を適用して新たな変数を作成します。
変換 すでにある変数値に変換を適用して新たな変数を作成します。 追加 選択位置に変数を挿入(
追加 選択位置に変数を挿入( )または最後に変数を追加(
)または最後に変数を追加( )します。
)します。 削除 選択した変数を削除します。
削除 選択した変数を削除します。 フィルタ 変数にフィルタを設定します。
フィルタ 変数にフィルタを設定します。
このタブに含まれている「編集」や「計算」などのボタンは,データタブに含まれるものと機能は同じですので,これらのボタンの使い方については「データ変数」のところで説明することにします。
データタブ
データタブはデータの入力や編集の際に使用します。見た目はExcelなどの表計算ソフトによく似ています(図 3.3)。
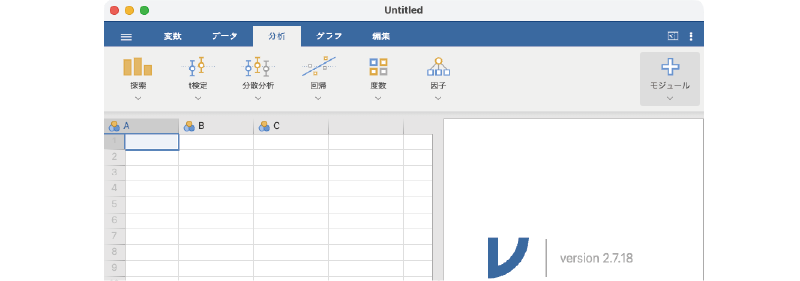
このタブのリボンには,次のツールボタンが含まれています。
- クリップボード データのコピー(
 )や貼り付け(
)や貼り付け( ),切り取り(
),切り取り( )などに使用します。使い方はWordやExcelなどと基本的に同じです。
)などに使用します。使い方はWordやExcelなどと基本的に同じです。 - 編集 操作の取り消し(),やり直し()を行います。
- 変数 変数の設定や変数値の処理に使用するツール群です。
- 設定 データの種類や変数名の設定を行います。
- 計算 すでにある変数値から新たな変数を作成します。
- 変換 すでにある変数値に変換を適用して新たな変数を作成します。
 重みづけ 集計済みのデータを分析する際などに,変数値に重みをつけるために使用します。
重みづけ 集計済みのデータを分析する際などに,変数値に重みをつけるために使用します。- 追加 スプレッドシートの選択位置に変数(列)を挿入()または列の最後に追加()します。
- 削除 スプレッドシート上で選択した変数(列)を削除します。
- 行 データ行の追加や削除に使用するツール群です。
- フィルタ 特定の条件に適合する行のみ表示させたい場合(男性のみ,女性のみ,など)に使用します。
 追加 選択部分にデータ行を挿入(
追加 選択部分にデータ行を挿入( )または最後の行にデータ行を追加(
)または最後の行にデータ行を追加( )します。
)します。 削除 選択行を削除します。
削除 選択行を削除します。
変数操作に関するボタン群,データ行の編集に関するボタン群の詳しい使い方については「データ変数」の操作のところで説明します。
分析タブ
分析タブは,統計分析を行う場合に使用します。画面の見た目は変数タブやデータタブと同じですが,リボンの部分が分析用の各ツールボタンになります(図 3.4)。

このタブのリボンには,次の分析用ツールボタンが含まれています。
 探索 平均値などの基本統計量の算出やグラフの作成に使用します(
探索 平均値などの基本統計量の算出やグラフの作成に使用します( t検定 1つあるいは2つの平均値の差の検定を行います(
t検定 1つあるいは2つの平均値の差の検定を行います( 分散分析 3つ以上の平均値の差の検定を行います(
分散分析 3つ以上の平均値の差の検定を行います( 回帰分析 回帰分析と呼ばれる手法を用いて変数間の関係を分析します(
回帰分析 回帰分析と呼ばれる手法を用いて変数間の関係を分析します( 度数分析
度数分析  因子分析 因子分析を実施します(
因子分析 因子分析を実施します(このように,分析タブのツールは分析手法ごとに非常にわかりやすく整理されています。また,これらの基本メニューに加え,画面の一番右には「 モジュール」というツールもあります。これはjamoviにさらに高度な機能を追加したい場合に使用します1。
モジュール」というツールもあります。これはjamoviにさらに高度な機能を追加したい場合に使用します1。
これら分析ツールの使用方法については,「分析編」で詳しく説明します。
グラフタブ
jamoviには,各分析ツールにそれぞれの分析に適したグラフを作成する機能が用意されていますが,そこで作成されるグラフは分析結果の一部として表示されるもので,グラフの編集機能も限られています。グラフタブは,分析ツールで作成されるグラフとは別に,データを可視化するためのグラフを作成したい場合に使用します(作図編を参照)。

このタブのリボンには,次のグラフ作成用ツール・ボタンが含まれています。
- 棒グラフ グループ間で値の大小を比較したい場合などに使用します。
- 箱ひげ図 複数グループにおけるデータの中央値やばらつき,外れ値などを示したい場合に使用します。
- ヒストグラム 階級ごとの度数の分布を視覚化したい場合に使用します。
- 散布図 相関関係など,変数間の関係を視覚化したい場合に使用します。
- 折れ線グラフ 時系列に伴う値の変化などを視覚化したい場合に使用します。
編集タブ
編集タブでは,フォントや段落の設定など,編集に関連したツールボタンがリボンに表示されます(図 3.6)。
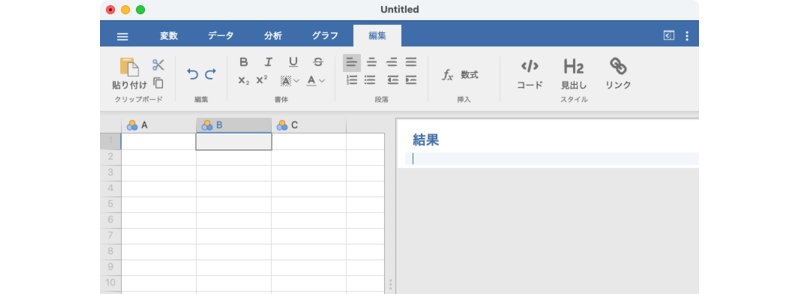
このタブのリボンに含まれるツールは次のとおりです。
- クリップボード データタブのボタンと同じです。
- 編集 データタブのボタンと同じです。
- 書体 文字を太字にしたり,斜体にしたりする際に使用します。
- 段落 文字全体を中央揃えにしたり,箇条書きにしたりなど,段落の書式を変更する際に使用します。
- 挿入 メモに数式を含めたい場合に使用します。数式はTeX形式で記述します2。
- スタイル その他の文書スタイルを設定するためのツール・ボタン群です。
 コード メモ中に分析プログラムを記載したい場合に使用します。
コード メモ中に分析プログラムを記載したい場合に使用します。 見出し 指定した部分を「見出し」行にしたい場合に使用します。
見出し 指定した部分を「見出し」行にしたい場合に使用します。 リンク メモにリンクを挿入したい際に使用します。
リンク メモにリンクを挿入したい際に使用します。
これらのボタンは,いずれも結果ウィンドウの内容を編集したり,メモを作成したりする際に用いられるものです。
3.2 データ変数
jamoviが扱う変数には,データ変数,計算変数,変換変数の3種類があります3。このうち,もっとも基本的で重要なものがデータ変数です。ここではまず,データ変数を用いてjamoviにおけるデータの操作方法を見ていきましょう。
データ変数は,調査や実験で得られた測定値(データ値)を格納するための変数で,jamoviにおける分析の基本となるものです。データファイルから読み込んだ値は,すべてデータ変数として扱われます。また,データ変数の値はスプレッドシートに直接入力することもできます。
データファイルからデータを読み込む方法についてはすでに第2章の「ファイル操作」で説明しましたので,ここではデータタブのスプレッドシートを用いたデータの編集方法について見ておきましょう。
3.2.1 スプレッドシートでの入力
スプレッドシートでの入力は,Excelの操作によく似ています。入力したいセル(マス目)をマウスクリックし,キーボードから値を入力するだけです。入力後,「Enter」キーまたは「↓」キーを押すと次の値が入力できるようになります。
基本的に,統計処理をするデータは各行が1人分(あるいは1試行分)の測定値で,各列はさまざまな変数(参加者番号や年齢,性別など)となります。なお,jamoviを起動した直後の画面にはA,B,Cの3つの変数しかありませんが,4列目以降にも値を入力することができます。空白の列に値を入力すると,その列は新たなデータ変数として扱われます。
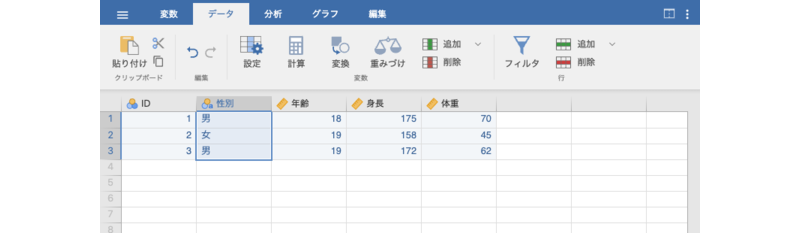
では,実際にスプレッドシートにデータを入力してみましょう。ここでは表 3.1のデータを用いることにします。変数タブが選択されている場合には,データタブを選択してスプレッドシートを表示させてください。
| ID | 性別 | 年齢 | 身長 | 体重 |
|---|---|---|---|---|
| 1 | 男 | 18 | 175 | 70 |
| 2 | 女 | 19 | 158 | 45 |
| 3 | 男 | 19 | 172 | 62 |
スプレッドシートの1列目(Aの列)にIDの値,2列目に性別の値を入力してください。なお,性別については「男」を「1」,「女」を「2」として入力してください。また,3列目から5列目には「年齢」,「身長」,「体重」の値をそれぞれ入力しましょう。変数名は後で設定しますので,ここでは数値を入力するだけです。
入力が終わった状態では,画面は図 3.7のようになっているはずです。
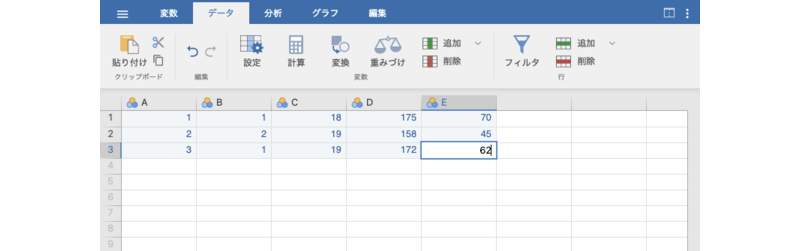
このように,jamoviではExcelなどの表計算ソフトを操作する感覚で簡単にデータ入力を行うことができます。
3.2.2 行・列の編集
今度は,入力済みデータを行・列の単位で編集する方法についてみてみましょう。jamoviでは,データの行と列はそれぞれ異なった意味をもちますので,追加・削除のメニューは行と列のそれぞれに別々に用意されています(図 3.8)。

行の編集
基本的に,jamoviではスプレッドシートの行は「参加者1人分のデータ」を意味します。つまり,スプレッドシートに25行のデータが入力されていれば,それは参加者25人分のデータがあるということです。
すでに入力されているデータに新たな参加者のデータを追加する場合は単純で,データがまだ入力されていない行にデータを入力するだけです。そうでなく,途中にデータを追加したい場合には,データを挿入したい部分を選択してリボンの「行」にある「追加」から「挿入」を選択します(図 3.9)。
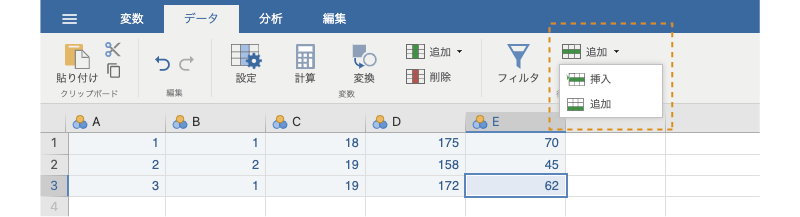
なおこの際,「挿入」の代わりに「追加」を実行すると,データの最後に新しい行が追加されます。
また,不要な行がある場合には,その行を選択し,リボンの「行」の部分にある「削除」を実行します(図 3.10)。

なお,これらの操作は,右クリックで表示されるメニューからも行うことができます(図 3.11)。
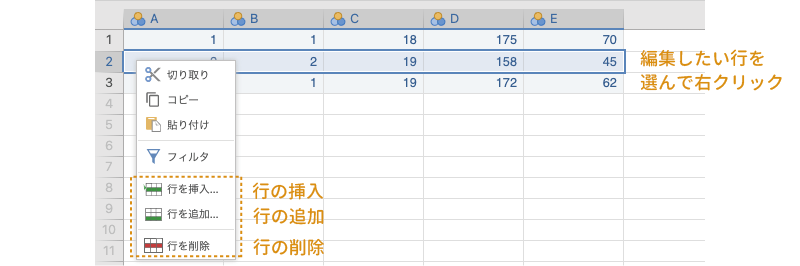
列の編集
jamoviスプレッドシートの列は,変数(回答者番号や年齢,性別,回答値,測定値など)として扱われます。列の編集方法も基本的には行の編集方法と同じで,列(変数)を追加・削除したい箇所を選択してから,データタブの「変数」にある「追加」または「削除」を実行するだけです。
ただし,jamoviが扱う変数には「データ変数」,「計算変数」,「変換変数」の3種類がありますので,変数を追加する際にはどの種類の変数を追加するのかを指定しなければなりません(図 3.12)。
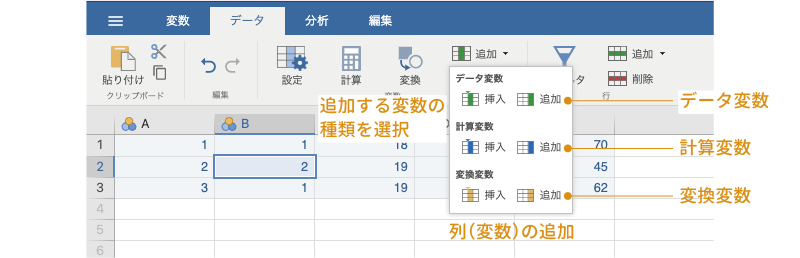
なお,jamoviの現在のバージョンでは,変数の順序を並び替えることができません。変数を追加する場合には,追加する場所をよく考えてからにしましょう。
データ変数の設定
空白のスプレッドシートにデータを入力した場合,そのままでは変数名が「A」,「B」,「C」などになっていて,どの列が何のデータなのかがわかりにくいですね。そこで,先ほど入力したデータを用い,基本的な変数設定の方法を見ておきましょう。
「A」列の変数名の部分(「A」の部分)をダブルクリックするか,または「A」列を選択してからリボンの「 設定」ボタンをクリックしてください(図 3.13)。
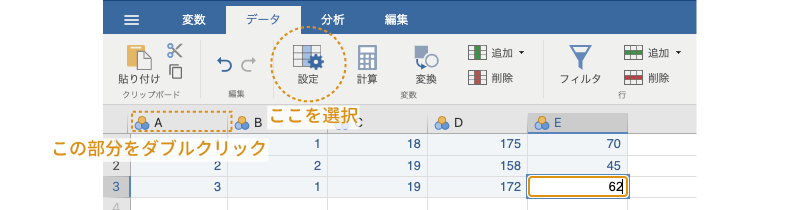
すると,データ変数の設定パネルが表示されますので(図 3.14),この画面の「データ変数」の欄に変数名を入力します。データの1列目には「ID」が入力されているので,変数名は「ID」としておきましょう。
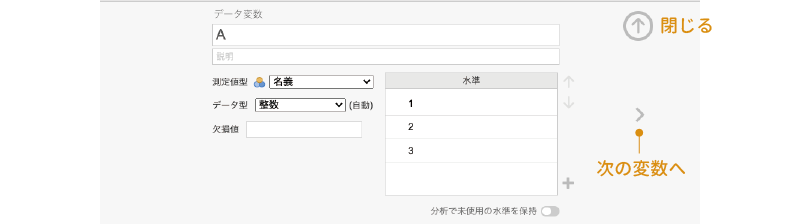
変数名には日本語を使用することも可能です。ただし,グラフなどの一部の機能で日本語がうまく表示されないことがありますので,そうしたトラブルを避けたければ,変数名はアルファベットと数字の組み合わせにしておいた方がいいでしょう。本書では,わかりやすさを重視して変数名に日本語を用いることにします。
その下の「説明」の欄は,変数の説明を記入する部分です。この欄は分析には影響しませんので,ここは空欄でも構いません。
1列目の変数名の設定が終わったら,画面右横の「![]() (次へ)」をクリックして2列目以降の変数名も設定しましょう。2列目の変数名は「性別」,3列目以降はそれぞれ「年齢」,「身長」,「体重」としておきます。
(次へ)」をクリックして2列目以降の変数名も設定しましょう。2列目の変数名は「性別」,3列目以降はそれぞれ「年齢」,「身長」,「体重」としておきます。
測定値型
設定パネルの「測定値型」は,変数の尺度型の設定です。データ変数には,測定値の尺度水準に応じて次の4つの型があります(図 3.15)。
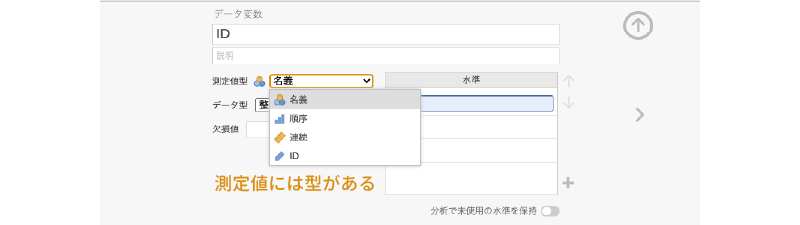
 名義 名義尺度で測定されたデータです。
名義 名義尺度で測定されたデータです。 順序 順序尺度で測定されたデータです。
順序 順序尺度で測定されたデータです。 連続 比率尺度や間隔尺度で測定されたデータです。
連続 比率尺度や間隔尺度で測定されたデータです。 ID 参加者番号など,それぞれのデータを識別するために用いる特殊なデータ型です。
ID 参加者番号など,それぞれのデータを識別するために用いる特殊なデータ型です。
データ変数の尺度型によって使用可能な分析手法が変わってきますので,変数の尺度型は適切に設定しましょう。なお,それぞれの変数がどの尺度型として扱われているのかについては,スプレッドシートの変数名の横にあるアイコンで確認することもできます。
データ1列目のID変数は個人を特定するための番号ですので,尺度タイプは「 ID」型にしておきましょう。2列目の「性別」変数は「 名義」型,「年齢」から「体重」まではすべて「 連続」型です。
データ型
データ変数には,さらに「整数」,「小数」,「文字」というデータ型の区別もあります。
「整数」型は,「1」や「15」など,測定値に小数値が含まれない場合,「小数」型は,「1.5」や「7.49」など,測定値に小数値が含まれる場合です。この2つのデータ型は画面上の表示方法がやや異なるくらいで本質的な違いはありませんが,「小数」型は尺度型が「連続」の場合にしか指定できません。「文字」型は,入力されたデータ値を「数値」としてではなく「文字」として扱います。「文字」型を指定できるのは,「 名義」型または「 順序」型の場合のみです。
ほとんどの場合,データ型についてはjamoviが自動的に判定してくれますので,設定の必要はないでしょう。何からの理由でデータ型を指定したい場合,データ変数の測定型と指定できるデータ型の関係は表 3.2のとおりです。
| 小数 | 整数 | 文字 | |
|---|---|---|---|
| 名義 | × | ○ | ○ |
| 順序 | ○ | ○ | ○ |
| 連続 | ○ | ○ | × |
欠損値
「欠損値」の欄では,データ中の欠損値の指定を行います。たとえば,1〜5の5段階尺度で得られたデータで未回答の部分を「9」として入力したようなデータの場合には,ここで「9」を欠損値として指定することができます。
今回のサンプルデータには欠損値はありませんので,ここは空欄のままにしておいてください。
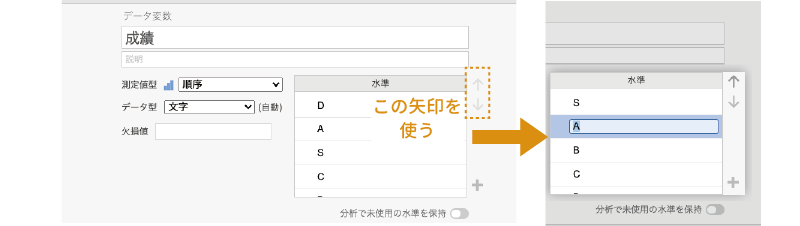
水準
「水準」は,その変数が「 順序」型あるいは「 名義」型の場合に使用できます。たとえば「S・A・B・C・D」の5段階で入力された成績評価データがあったとします。そしてそのデータでは,1人目が「D」,2人目が「A」,3人目が「S」,4人目が「C」というようなものだったとしましょう。この場合,そのままではこの変数値が「D・A・S・C・B」という順で扱われたり,あるいはアルファベット順に「A・B・C・D・S」という順に扱われたりしてしまいます。なぜなら,統計ソフトには成績のよい方から「S・A・B・C・D」の順であるという知識はないからです。
このような場合には,この「水準」の右横にある上下矢印で変数値を適切な順番に並べ替えることで,分析においても「S・A・B・C・D」という順が維持されるようになります(図 3.16)。
また,今回のサンプルデータのように,「性別」の値で男性が「1」,女性が「2」と入力されている場合,分析結果の出力画面には性別の値は入力値のまま「1」や「2」と表示されるのですが,「1」や「2」という表示ではどちらが男性でどちらが女性なのかがわかりづらいですね。もし,男女をとり違えて結果を解釈してしまったら大変です。
そのような場合,この「Levels」の「1」の欄に「男」,「2」の欄に「女」と入力し,それぞれの値に変数ラベルをつけることができます。そうすると,データ画面上や結果の表示では性別データの「1」が「男」,「2」が「女」と表示されるようになり,男女のとり違えといったミスを防ぐことができるのです(図 3.17)。
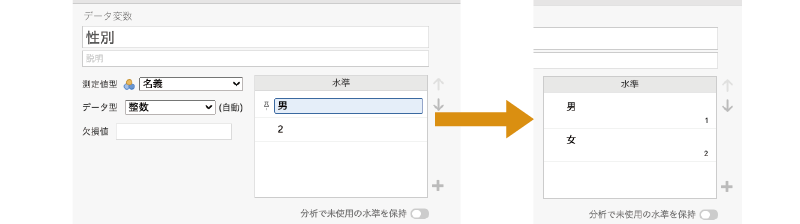
このようにして変数ラベル設定した場合,本来の変数値は「水準」欄の右下で確認できます。
なお,その下にある「分析で未使用の水準を保持」のスイッチを「オン」にした場合,データの修正などによって特定の水準値を含む行の数が0になった場合にもその水準値が保持されます。ここを「オフ」にした場合には,データ中に含まれていない水準値は「水準」から削除されます。
さて,これでサンプルデータの入力と設定は完了です。変数の設定パネルを閉じるとスプレッドシートは図 3.18のようになっているはずです。
3.3 計算変数
実際のデータ分析では,複数の質問項目の回答値から参加者ごとに合計得点を算出したり,平均値を算出したりして,それをデータとして使用する場合が多々あります。このように,他の変数値を用いた計算の結果を新たな変数値として使用するのが「計算変数」です。
3.3.1 計算変数の作成
先ほど作成したデータを使って計算変数の作成方法について見てみましょう。ここでは,身長と体重のデータから,各個人のBMI値(体格指数)を算出することにします。
計算変数を使用するには,スプレッドシートで列名が空欄になっている部分をダブルクリックするか,その列を選択してリボンの「 設定」ボタンをクリックします。すると,図 3.19のような変数作成画面が表示されますので,ここで「計算変数を作成」のボタンをクリックします。
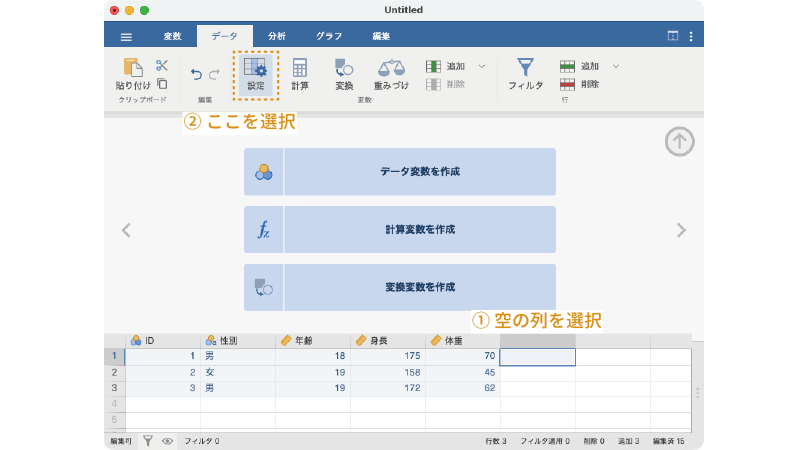
あるいは,新しい列を選択した状態でリボンの「 計算」ボタンをクリックしても,新しい列に計算変数が作成されて変数設定パネルになります。
計算変数の設定パネルは図 3.20のようになっています。変数名と説明の部分はデータ変数の場合と同じです。この計算変数の変数名は「BMI」としておきましょう。
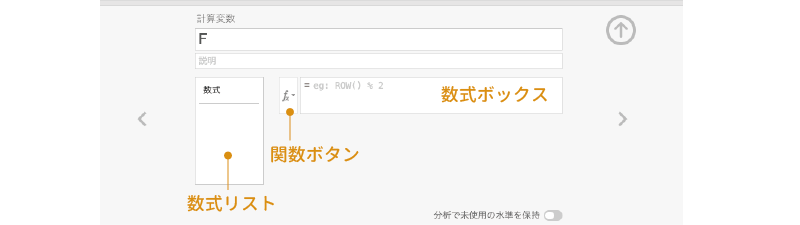
その下の部分はデータ変数の場合とだいぶ異なります。計算変数は,この設定パネルの中央,数式ボックスの「=」の後ろに計算式を入力して値を設定します。
3.3.2 計算変数の設定
では,早速BMI値を計算変数として設定しましょう。数式ボックスに計算式を入力します。BMIの値は,次のようにして求められます。
\[ \text{BMI} = \text{体重(kg)} \div \text{身長(m)}^2 \]
なお,BMIの式では身長はメートルで計算する必要があります。先ほど入力した身長データはセンチメートルで記録されているので,これを100で割ってメートルに変換するのを忘れないようにしてください。そのため,これを入力式の形に直すと「= 体重 / (身長/100)^2」となります。数式ボックスの「=」の後ろの部分をクリックし,この式を入力します。
このとき,変数名の入力ミスなどがあるとエラーになってしまいますので注意してください。変数名の入力ミスを防ぐには,数式ボックスのすぐ左隣にある「関数ボタン( )」を使うのがよいでしょう。この部分をクリックすると,「関数」と「変数」という画面が表示されます(図 3.21)。左側の「関数」の部分は,平均値などの計算用の関数のリストで,それぞれの関数名をクリックするとその関数簡単な説明が下側に表示されるようになっています。
)」を使うのがよいでしょう。この部分をクリックすると,「関数」と「変数」という画面が表示されます(図 3.21)。左側の「関数」の部分は,平均値などの計算用の関数のリストで,それぞれの関数名をクリックするとその関数簡単な説明が下側に表示されるようになっています。
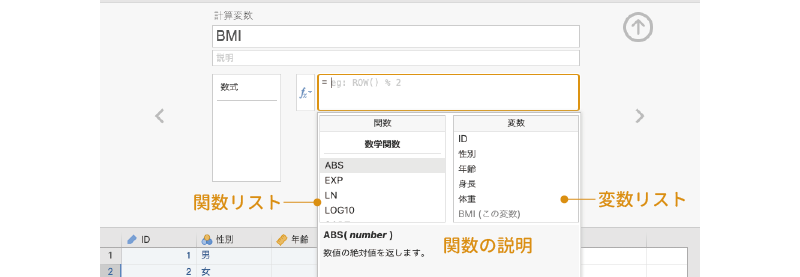
ここでは関数は使用しませんが,「関数」は,複数の質問項目の回答値を平均して合成得点を求めたりする場合に役立ちます。なお,計算変数に使用できる関数は,次のグループに分類されています。これらの関数の詳細については付録にまとめてありますのでそちらを参照してください。
- 数学関数 絶対値(ABS),指数(EXP),対数(LN)など,数学的な計算を行う関数群です。
- 統計関数 合計値(SUM),平均値(MEAN)など,基本的な統計量を算出する関数群です。
- 論理関数 条件に応じて異なる計算を行いたい場合に使用する関数群です。
- 文字関数 文字データを結合したり,数値を文字に変換したりする場合に使用する関数群です。
- 参照関数 特定の条件に合致するセルを指定して計算を行いたい場合などに使用します。
- その他 数値と文字の変換など,その他の処理を行うための関数群です。
- シミュレーション 特定の確率分布をもつデータを擬似的に作成したい場合に使用します。
この画面で,「変数」にある「体重」をダブルクリックすると,その変数名が数式ボックスに入力されます。こうした機能を使いながら,計算変数の数式を完成させましょう。なお,数式に使用する文字は,変数名を除いてすべて半角(英数入力モード)で入力する必要がありますので,その点は注意をしてください。式を入力し終わったら,キーボードの「Enter(Return)」キーを押して式を確定させます。
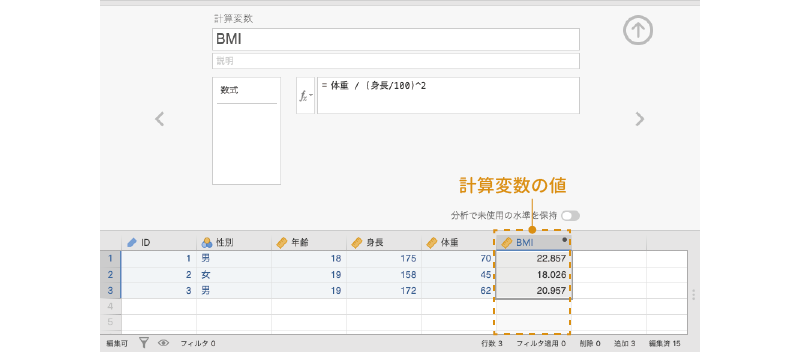
すると,スプレッドシートの「体重」の横に「BMI」という変数が作成され,そこに各個人のBMI値が表示されます(図 3.22)。なお,この計算変数に格納されているのは式だけですので,計算変数の作成後に計算に使われている変数(「体重」と「身長」)の値が変更されると自動的に再計算されて新しい値に更新されます。計算変数は,スプレッドシートでは変数名の右上部分に黒丸がついた状態で表示されます。
計算変数の計算式を修正したい場合には,計算変数のタイトル部分をダブルクリックするか,修正したい計算変数の列を選択したうえで「 設定」ボタンをクリックしてください。
3.4 変換変数
質問紙調査のデータで逆転項目が複数ある場合,その回答値の逆転処理は計算変数でも可能ですが,逆転項目がたくさんある場合,その1つ1つに対して計算式を入力して計算変数を作成するのは面倒ですし,途中でミスが発生する可能性も増大します。
このように,複数の変数に対して同じ処理を繰り返し実施したい場合には,「変換変数」が便利です。変換変数は,空の列の列名をダブルクリックして変数作成画面を開き,そこで「変換変数を作成」を選択するか,リボンの「 変換」ボタンをクリックすることで作成できます。
サンプルデータでは変換変数を使う必要性はとくにありませんが,せっかくなので使ってみましょう。ここでは,身長の測定値をcmからmに変換する処理を,変換変数を使って行ってみます。
スプレッドシートで「身長」の列を選択したら,リボンの「 変換」をクリックして変換変数を1つ作成してください。「身長」を選択してから「 変換」をクリックすると,変数名などが自動で入力された状態で設定パネルが開きます(図 3.23)。
変数名は,これがメートル単位の身長だということがわかりやすいように「身長 (m)」としておきましょう。その下の「変換元の変数」の部分は,変換を適用する変数を指定します(図 3.24)。「身長」の列を選択してから変換変数を作成した場合,ここは自動的にその変数が選択された状態になります。もし変換対象とは異なる変数が指定されている場合には,適切な変数を選択してください。
変換対象を適切に設定したら,その下の「使用する変換」の部分で適用する変換を指定します。今はまだ適用できる変換がありませんので,「変換を新規作成…」を選択して変換を作成しましょう(図 3.25)。
すると,図 3.26のような設定パネルが表示されます。
最初の部分はこの変換の名前です。再利用する際に便利なように,できるだけわかりやすい名前をつけておきましょう。今回の変換はセンチメートルからメートルへの変換ですので,「cm -> m」という名前にしておきます。
その下の「説明」の部分は変換の説明です。変換名からどのようなことをしているのかがわかるようであればここは空欄で構いませんが,そうでない場合はここに簡単に説明を書いておいたほうがよいでしょう。
この「説明」の隣の「変数の接尾辞」は,この変換を適用した後の変数名の末尾に自動的につける文字を設定します。ここでは空欄にしておきますが,たとえば逆転項目の逆転処理を行うような変換の場合には,ここに「R」と設定しておけば,「Q1 - R」,「Q2 - R」のように,変換後の変数名として元の変数名(「Q1」や「Q2」など)の末尾に「- R」をつけた名前が自動的に設定されるようになります。
関数ボタンと数式ボックスの使用方法は計算変数の場合と同じです。必要に応じて関数ボタンで変数名や関数を選択し,数式ボックスの中に変換式を記入します。今回の変換ではセンチメートルで記録された身長のデータをメートルに変換するので,数式ボックス内の式は「$source / 100」となります(図 3.27)。なお,「$source」は変換元の値を意味します。
ここでは使用しませんが,変換ボックスのすぐ上にある「変換条件を追加」を用いれば,元の値の範囲に応じて異なる変換式を適用するようなこともできます。
変換式が完成したら,「Enter(Return)」キーで式を確定し,設定パネルを閉じてください。
すると,「使用する変換」の部分が先ほど作成した「cm -> m」になっているはずです(図 3.28)。この変換変数も,計算変数の場合と同様に,変換元の変数値が変化すると自動的に値が更新されます。また,この変換式は,その右横にある「編集…」ボタンをクリックすることで修正可能です。変換変数は,スプレッドシートでは変数名の欄の右上に赤丸がついた状態で表示されます。
変換対象の変数が1つしかない場合には,計算変数と変換変数のどちらを用いてもあまり違いはありませんが,質問紙調査における逆転項目の処理のように,同じ変換を複数の変数に対して適用する場合には,1つの「変換式」を複数の変数に適用できる変換変数のほうが効率的でしょう。
3.5 重みづけ
通常,分析用データは1行に1人分のデータを入力します。しかし,年齢別・性別に集計されたデータのように,すでに集計済みのデータを分析したい場合もあります。このようなデータでそのまま平均値を求めると,各行に含まれる人数が反映されず,正しい値になりません。そこで,各行が何人分の集計なのかを示す重み変数を設定すると,集計済みデータも分析用データとして扱えるようになります。
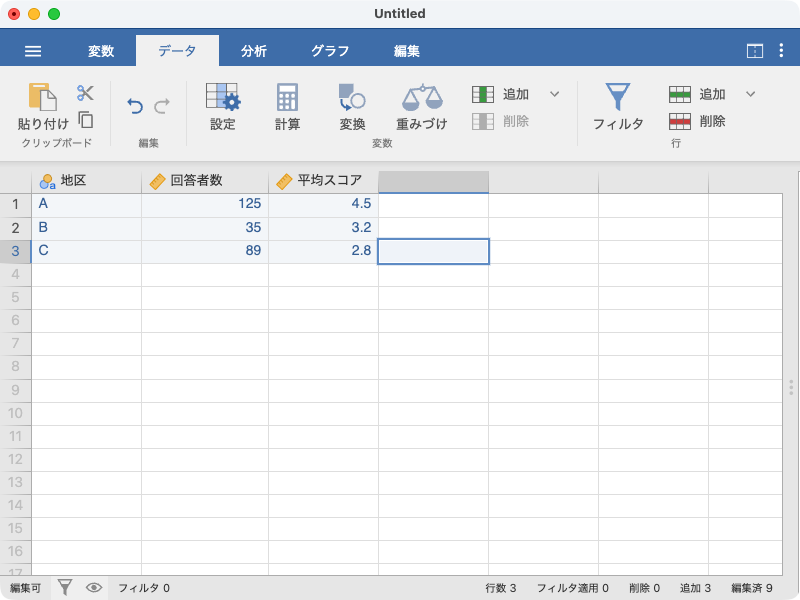
次の例を見てみましょう。このデータには,地区に集計されたある得点が入力されています(図 3.29)。各地区の回答者数は,それぞれ125人,35人,89人で,3列目の「平均スコア」は,各地区ごとの平均値です。このようなデータでは,回答者全体の「平均スコア」を算出したい場合にそのまま平均値を求めようとすると,単純にこの3つの値の平均値が算出されてしまい,回答者全体の平均値を求めることができません。
回答者の人数を考慮して全体の平均値を求めたい場合には,各行を回答者数で重みづけする必要があります。リボンの「 重みづけ」をクリックすると,図 3.30のような設定パネルが表示されます。
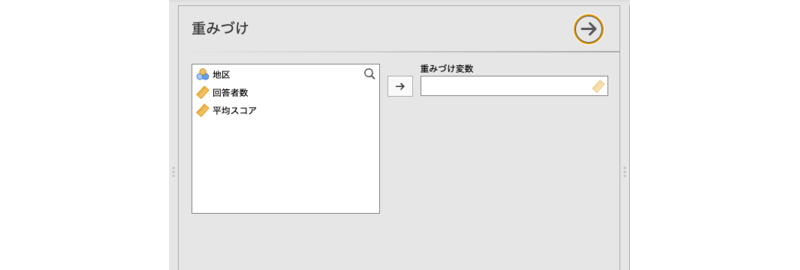
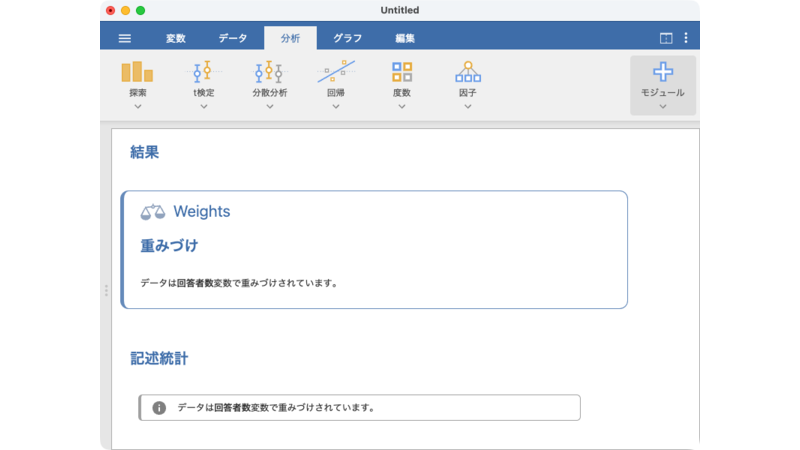
設定パネルの左側は,データに含まれる変数一覧です。ここから「回答者数」を選択し,それをダブルクリック,またはマウスでドラッグして右側の「重みづけの変数」に移動させると,結果ウィンドウに次のように表示され(図 3.31),以後の分析では回答者数を考慮した値が算出されるようになります。この状態で,「平均スコア」の平均値を求めると,その値は3つの値の平均値ではなく,249人の回答値の平均値になるのです。
3.6 フィルタ
データ分析では,データ全体のうちの一部だけを使って分析したいということもよくあります。たとえば,男性のデータだけを分析したいとか,小学校低学年の児童のデータだけを分析したいとかいうような場合です。そのような場合,分析のたびに全体のデータファイルから特定の行を抜き出し,それを別のデータファイルとして作成するというのも1つの方法ですが,そのような方法はかなり手間がかかりますし,対象データを抜き出す過程でミスが生じる可能性も高くなります。
jamoviには,そのような場合に便利なフィルタと呼ばれる機能が搭載されています。フィルタは条件に合致するデータ行だけを表示し,それ以外を非表示にすることができる機能で,フィルタをオンにしている間は,表示されているデータのみが分析の対象となります。また,フィルタはいつでも簡単にオン・オフの切り替えができますので,男女別や学年別にデータファイルを別々にしなくても,フィルタを使えば男女別の分析や特定の学年のみを対象とした分析が簡単に実行できるのです。
では,これまでに使用してきたサンプルのデータを用いてフィルタを体験してみましょう。ここでは,フィルタを使って男性のデータだけを抽出してみます。
フィルタを使用するには,リボンの「 フィルタ」をクリックします。すると,図 3.32のような設定パネルが表示されます。
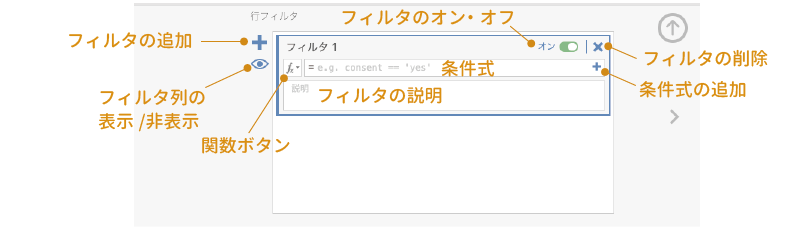
設定パネルの左側にあるボタン( )はフィルタの追加ボタンです。フィルタは必要に応じて複数設定することができます。その下の目の形をしたアイコン(
)はフィルタの追加ボタンです。フィルタは必要に応じて複数設定することができます。その下の目の形をしたアイコン( )は,フィルタにあてはまる行だけを表示させるかどうかを切り替えるボタンです。
)は,フィルタにあてはまる行だけを表示させるかどうかを切り替えるボタンです。
画面中央の部分がフィルタの条件式を設定する部分で,最初の関数ボタンとボックスは計算変数や変換変数の場合と基本的には同じです。ただ,ここには計算式ではなく,表示させるデータの条件を示す式を記入します。条件式を複数使用したい場合は,ボックスの右側にある小さいほうの「」ボタンをクリックすると条件式を追加できます。
その下の「説明」の部分は,そのフィルタについての説明欄です。後から見返したときにそのフィルタが何のためのものなのかがわからなくならないように,説明をきちんと書いておきましょう。条件式ボックスの右上にあるのは,そのフィルタのオン・オフの切り替えスイッチとフィルタの削除ボタンです。
では,男性のデータだけを表示させるフィルタを作成しましょう。条件式のボックスに「性別 == 1」と入力してください。このとき,「性別」と「1」の間の等号(=)は2つ連続で入力する必要がある点に注意してください。式を入力して確定すると,スプレッドシートの表示が図 3.33のようになります。
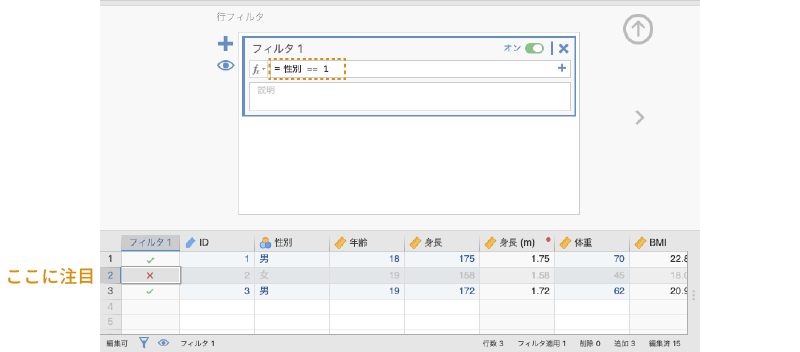
「フィルタ1」の列に「 」が表示されているのがこのフィルタの条件にあてはまるデータ行,「
」が表示されているのがこのフィルタの条件にあてはまるデータ行,「 」が表示されているのがフィルタにはあてはまらないデータ行です。見てわかるように,性別が「男」の行だけ「」になっています。また,フィルタ設定パネルあるいはスプレッドシート下部にあるアイコンをクリックすると,フィルタにあてはまらない行を非表示にすることができます(図 3.34)。
」が表示されているのがフィルタにはあてはまらないデータ行です。見てわかるように,性別が「男」の行だけ「」になっています。また,フィルタ設定パネルあるいはスプレッドシート下部にあるアイコンをクリックすると,フィルタにあてはまらない行を非表示にすることができます(図 3.34)。
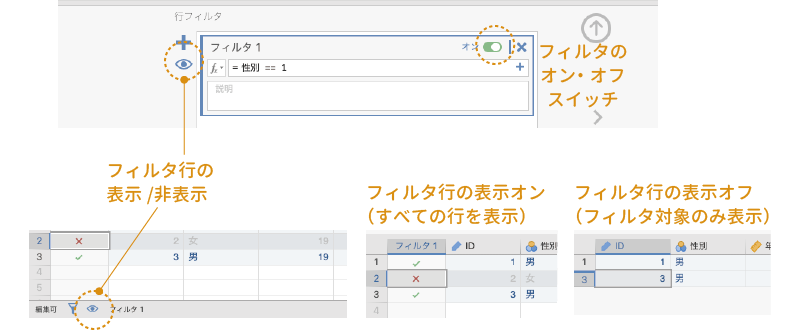
フィルタ設定パネルの条件式ボックス右上にあるスイッチでは,フィルタのオン・オフをフィルタごとに個別に切り替え可能です。フィルタを使用しない場合は,忘れずに「オフ」にしておきましょう。
なお,「20代の女性で〜な人のみ」というような複雑な条件でデータを抽出する場合は,複雑な条件式のフィルタを1つ作るよりも,「20代の女性」,「〜な人」というシンプルなフィルタを作成し,それらを組み合わせて使用するほうがよいでしょう。そうすることで,思いどおりの結果が得られない場合にどのフィルタ条件がおかしいのかを簡単に突き止められるようになります。
3.7 変数タブの使用
ここまでの作業で作成した変数やフィルタは,「変数」タブで一覧することもできます。図 3.35は,ここまでに作成した変数やフィルタに「説明」をいくつか追加した状態です。このように,変数タブでは変数名と変数の説明がウィンドウに一覧表示されるので,変数名を英数字にして「説明」欄に日本語で説明を記入した場合や,質問紙調査データで「説明」欄に質問文を入力した場合などには,このタブは重宝することでしょう。
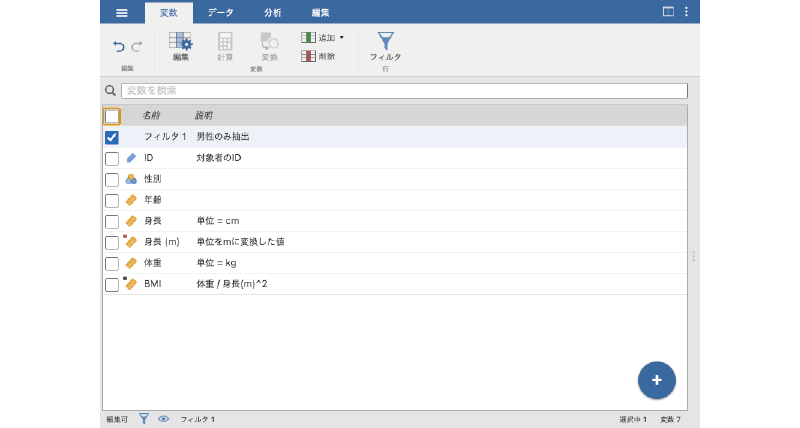
変数タブでは,大きな+ボタンを使用して各種変数を挿入したり追加したりすることも可能です。変数の設定や追加・削除の方法は,データタブのスプレッドシート上での操作と同じなのでここでは省略します。
3.8 演習:調査票データの処理
ここまで,jamoviにおけるデータ操作方法の基本についてひととおり見てきましたので,ここでは実際の分析場面により近い形で実践してみましょう。まず,練習用データファイル(basics_data01.omv)をjamoviで開いてください。
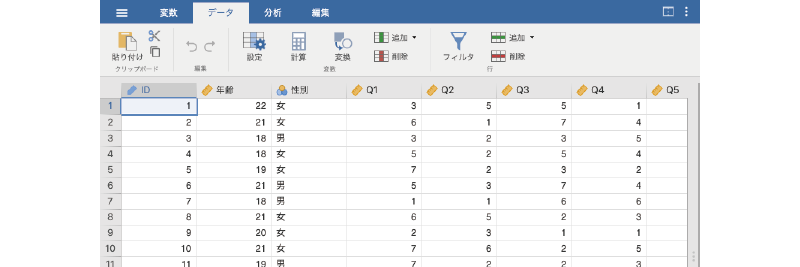
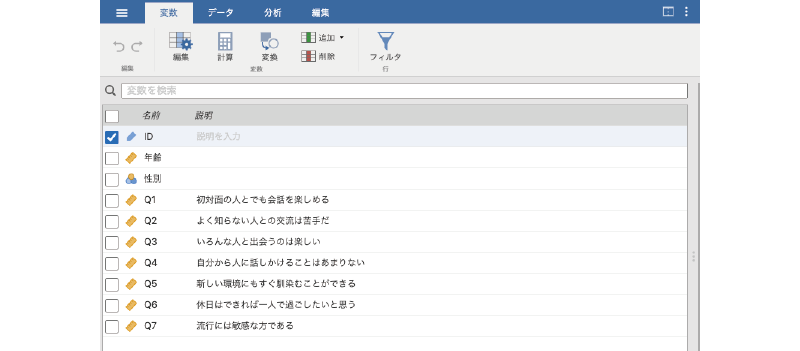
このデータファイルには,「ID」,「年齢」,「性別」の各変数値と,「Q1」から「Q7」までの回答値が入力されています(図 3.36)。「Q1」から「Q7」は,それぞれ「外向性」を測定する心理尺度の回答データで,いずれも「まったくそう思わない(1)」から「とてもそう思う(7)」までの7段階で回答されています。「Q1」から「Q7」の質問内容は,変数タブで確認することができます(図 3.37)4。
この練習データを用い,調査票データの分析場面でよく用いられる次の処理について実践してみましょう5。
- 逆転項目の処理を行う
- 尺度得点を算出する
- 尺度得点に基づいて対象者をグループに分割する
3.8.1 逆転項目の処理
一般に,リカート法6などを用いた心理尺度では,1つの測定概念について複数の質問を用意して測定を行います。たとえば,「外向性」を測定したい場合には,「初対面の人とでも会話を楽しめる」や「いろんな人と出会うのは楽しい」といった,外向性の高さに関連する質問文を複数用意して,そのすべてに「まったくそう思わない(1)」から「とてもそう思う(7)」の7段階で回答させるということを行うわけです。
この際,それらの質問文の中には「よく知らない人との交流は苦手だ」のような,外向性の高さとは逆の内容の文が含まれていることがあります。このように,本来測定したいものとは逆の内容を含む質問文のことを逆転項目といいます(図 3.38)。

この練習データでは,偶数番号の質問(Q2,Q4,Q6)が逆転項目になっています。この場合,「Q1」や「Q3」の質問に対して6や7と回答した人は外向性が高いことになるのですが,「Q2」や「Q4」に「6」や「7」と回答した人は外向性が低いことを意味します。このように,逆転項目は他の項目とは点数の方向が逆になるため,その扱いには注意が必要です。通常,こうした逆転項目の回答値は,それ以外の回答値と向きがそろうように変換したうえで分析に用います。
jamoviでは,逆転項目は「計算変数」または「変換変数」を用いて処理することができます。どちらを用いても構いませんが,逆転項目が複数ある場合には,変換変数を用いたほうが手軽に処理できるでしょう。そこで,ここでは変換変数を用いて逆転項目を処理することにします。
変換変数の作成
それでは,「Q2」について逆転項目の処理を行いましょう。ここでは,「Q2」のすぐ後ろに,回答値を逆転した変換変数「Q2.R」を作成します。
まず,「Q2」の列名のところをクリックして,「Q2」の列を選択します(図 3.39)。
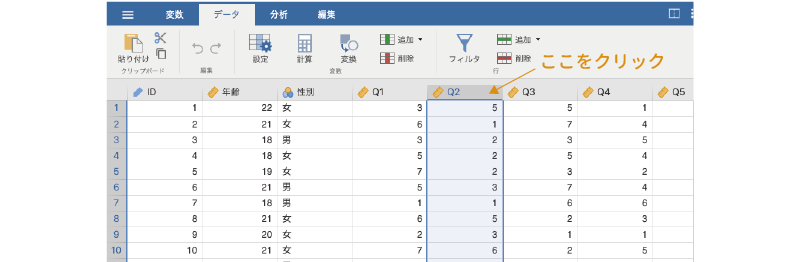
その状態でデータタブの「変数」にある「 変換」ボタンをクリックします(図 3.40)。
すると,図 3.41のような変換変数の設定パネルが表示されますので,作成した変換変数の名前を「Q2.R」に設定しましょう。このとき,「変換元の変数」の部分が「Q2」になっていることを確認してください。
次に,「使用する変換」のメニューから「変換を新規作成…」を選択して実行します(図 3.42)。
すると,図 3.43のような「変換」の設定パネルが表示されます。再利用の際にわかりやすいように,この変換の名前を「逆転項目」にしましょう。
そして「変換条件を追加」の数式ボックスに逆転のための変換式を設定します。
5段階尺度や7段階尺度の場合,逆転項目の変換式は次の形で求めることができます。
\[ \text{逆転項目の回答値} = (\text{回答段階の最大値}+\text{回答段階の最小値}) - \text{元の回答値} \]
練習データでは,「Q2」は「1」から「7」までの値で回答してもらう形式ですので,逆転項目を処理する際の変換式は次のようになります。
\[ \text{逆転項目の回答値} = (7+1) - \text{元の回答値} = 8 - \text{元の回答値} \]
そこで,変換式の部分を次のように設定します(図 3.44)。
= 8 - $source
画面右側の をクリックして変換の設定パネルを閉じ,
をクリックして変換の設定パネルを閉じ, で変数設定パネルを閉じると,「Q2」のすぐ後ろの列に「Q2.R」という変換変数が作成されていることが確認できます (図 3.45)。この変数が変換変数であることは,変数名の部分の右肩に小さな赤丸がついていることから判断できます。
で変数設定パネルを閉じると,「Q2」のすぐ後ろの列に「Q2.R」という変換変数が作成されていることが確認できます (図 3.45)。この変数が変換変数であることは,変数名の部分の右肩に小さな赤丸がついていることから判断できます。
この変数の値を確認すると,「Q2」の値が「1」の場合には「Q2.R」は「7」,「Q2」の値が「7」の場合には「Q2.R」は「1」というように,値が逆転しているのがわかると思います。
Q2の逆転処理はこれでおしまいです。次は「Q4」の逆転処理を行いましょう。「Q4」の列を選択して「 変換」をクリックすると,再び変換変数の設定パネルが表示されます。新しく作成した変換変数の名前を「Q4.R」に設定したら,「変換元の変数」の部分が「Q4」になっていることを確認し,「使用する変換」のメニューをクリックしてください。すると,メニュー項目の中に,先ほど作成した「逆転項目」があるはずです (図 3.46)。
この「逆転項目」を選択して変数設定パネルを閉じれば「Q4」の逆転処理は完了です。このように,一度作成した変換式は繰り返し利用できますので,逆転項目が複数ある場合には変換変数で逆転処理を行うのが便利です。
先ほどと同様の手順で,「Q6」についても逆転処理を行ってください。これで逆転項目の処理はおしまいです。
3.8.2 尺度得点の算出
「外向性」などの単一の概念について複数の質問文を用いて測定する場合には,それら複数の質問文に対する回答値を合計または平均し,それを尺度得点として用いるのが一般的です。ここでは,「Q1」から「Q7」までの回答の合計値を尺度得点として算出することにしましょう。なお,その際,「Q2」や「Q4」などの逆転項目については逆転処理を行った後の変数値(「Q2.R」や「Q4.R」など)を用いる必要がある点に注意してください。
この「外向性尺度」の尺度得点は,データの一番最後の列に新たな計算変数として作成しましょう。データタブの「変数」の欄にある「 追加」を使用して,新たな「計算変数」を「 追加」してください (図 3.47)。
追加」してください (図 3.47)。
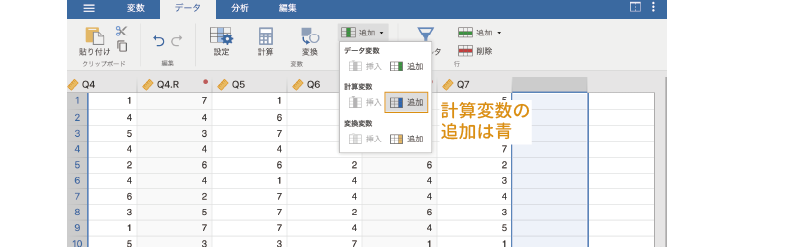
作成された計算変数の変数名部分をダブルクリックすると,変数の設定パネルが表示されます。変数名は「N」になっているかと思いますが,このままだと何の値か分からないので,変数名を「外向性」に変更します (図 3.48)。
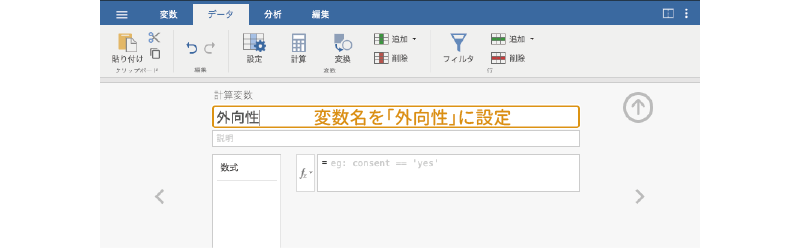
変数名の設定ができたら,その下の計算式の部分に,変数値を合計するための式を入力します。ここでは尺度得点として回答値の合計を用いるので,関数ボタン()で表示される関数の中から「SUM」を探してダブルクリックします (図 3.49)。この「SUM」という関数は,括弧の中に指定された値の合計値を求める関数です7。
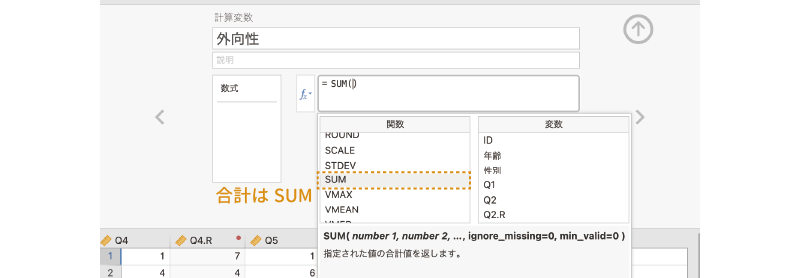
数式ボックスの中に「= SUM()」と入力されているのを確認したら,括弧の間に合計対象となる変数を記入していきます。この際,変数名はキーボードから入力してもよいですが,関数の右側に表示される変数一覧から必要な変数名をダブルクリックして入力したほうが,タイプミスの心配もなく,わかりやすいでしょう。今回,合計値の対象となるのは,「Q1」,「Q2.R」,「Q3」,「Q4.R」,「Q5」,「Q6.R」,「Q7」の7つの変数です。各変数の区切りにはコンマ(,)を使用します。変数名を1つ入力したらコンマ(,)を入力し,次の変数名を入力するようにしてください。また,コンマは必ず日本語入力をオフにした状態で入力してください。
完成した外向性得点の算出式は次のようになります (図 3.50)。
= SUM(Q1, Q2.R, Q3, Q4.R, Q5, Q6.R, Q7)
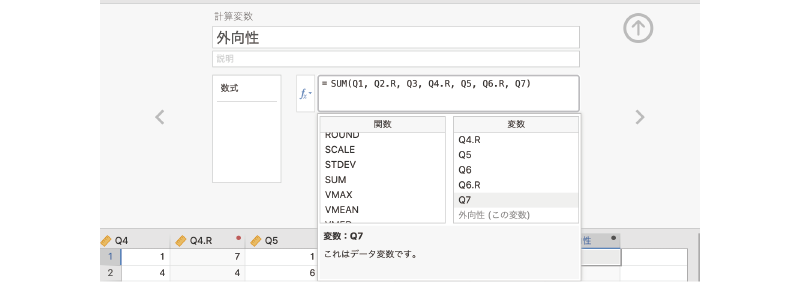
式の入力が終わったら,画面右のをクリックして変数設定パネルを閉じます。これで各対象者の外向性得点(合計値)が算出されました (図 3.51)。
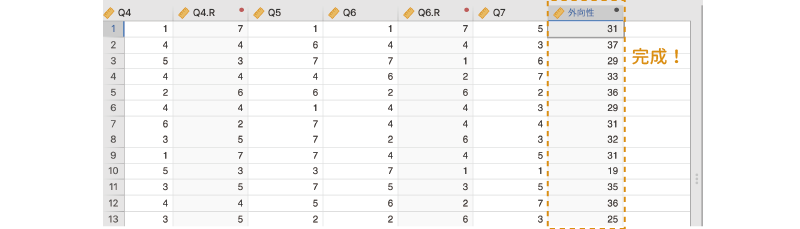
3.8.3 グループへの分割
実際の分析場面では,算出された尺度得点を元に,対象者を外向性が高い群と低い群に分けて分析するといったこともよく行われます。ここでは,外向性得点の平均値を基準に,平均値以上の人を外向性「高群」,平均値未満の人を外向性「低群」としてグループ分けする方法についてみていきます。
対象者を外向性の高・低2群に分割した結果は計算変数に格納しますので,「変数」の「 追加」から,新たな「計算変数」を「 追加」してください (図 3.52)。
そして新しく作成した計算変数の設定パネルを開き,変数名を「群」に変更しましょう (図 3.53)。
群に設定
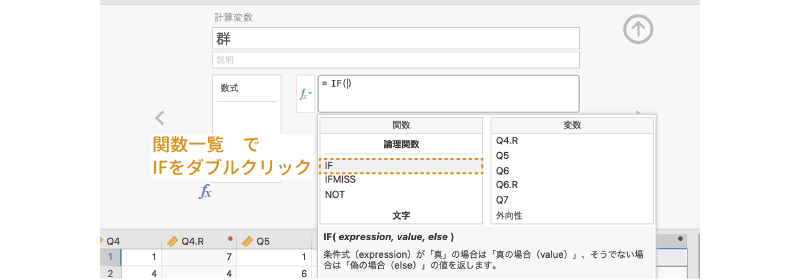
続いて,数式ボックスにグループ分けのための式を入力します。関数ボタン()で表示される関数一覧の中から,「IF」を選択してください (図 3.54)。このIF関数は,条件式の結果に応じて異なる値を設定できる関数です。
この「IF( )」の括弧の中には,次のように「条件式」,「条件式にあてはまる場合の値」,「条件式にあてはまらない場合の値」の3つをコンマで区切って指定します。
IF(条件式, あてはまる場合の値, あてはまらない場合の値)今回は,外向性得点の平均値を基準にして対象者を外向性高群と低群の2群に分割したいので,「条件式」の部分には各対象者の外向性得点が平均値以上であるかどうかを判断する式(\(\text{外向性得点} \geqq \text{外向性得点の平均値}\))を記入することになります。
そこでまず,変数名一覧から「外向性」をダブルクリックして括弧内に入力し,続けてキーボードから>=と入力します (図 3.55)。
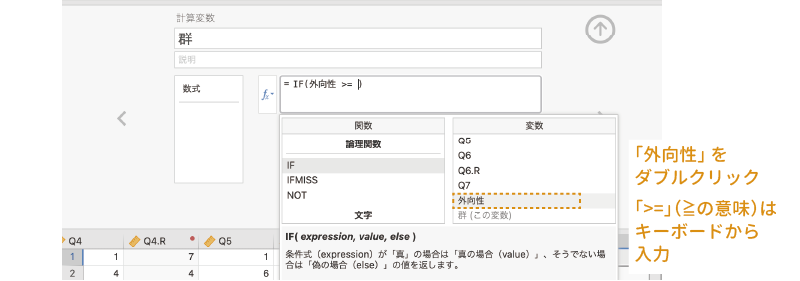
さらに,関数一覧から「VMEAN」を選択して入力します (図 3.56)。この「VMEAN」は,指定した変数の平均値を算出する関数です8。
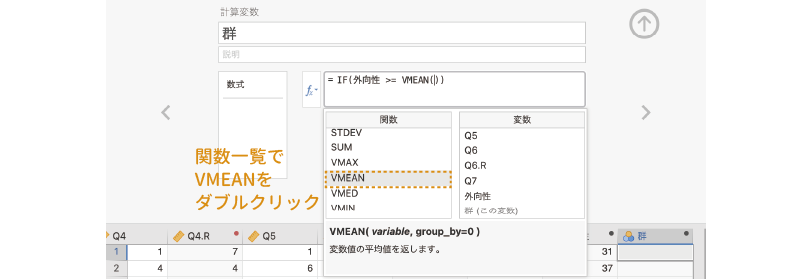
そしてこの「VMEAN」関数の括弧の中に「外向性」を指定します (図 3.57)。
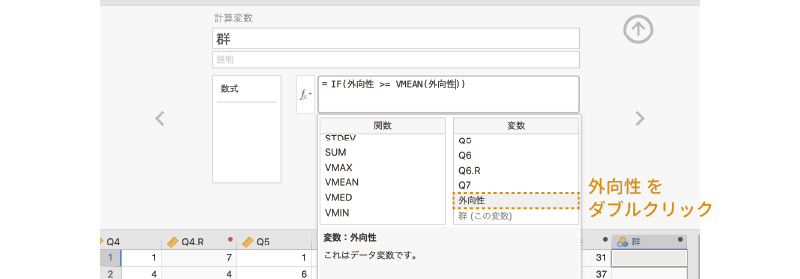
この「外向性 >= VMEAN(外向性)」の式が,「\(\text{外向性得点} \geqq \text{外向性得点の平均値}\)」を意味します。この条件式に続けて,条件式にあてはまる場合の値として「高群」,あてはまらない場合の値として「低群」を,それぞれコンマ(,)で区切って入力します (図 3.58)。このとき,変数値に「高群」や「低群」のような文字を用いる場合には,その値を引用符(““)で括る必要がありますので注意してください。
=IF(外向性 >= VMEAN(外向性), "高群", "低群")
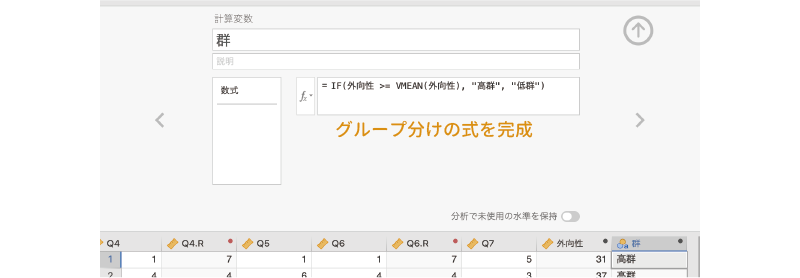
式を完成させて変数設定パネルを閉じると,新しく作成した「群」変数に「高群」または「低群」が値として入力されているのを確認することができます (図 3.59)。条件式の部分がやや難しく感じられたかもしれませんが,計算変数ではこのようにしてデータをグループ分けすることもできるのです。
このような,逆転項目の回答値の処理や尺度得点の算出,グループ分けといった処理は,Excelなどの表計算ソフトで行うこともできますし,そのほうが簡単だと思う人もいるかもしれません。しかし,表計算ソフトで処理をした場合,元のデータに入力ミスが見つかったなどの理由でデータに修正が生じた際には,これらの処理をやり直さなければなりません。
これに対し,jamoviでこれらの処理を行った場合には,仮に元のデータに修正が生じたとしても,計算変数や変換変数の値は自動的に最新の内容に更新されるため,計算し直す必要がありません。分析データを確実に最新の状態に保てることは,jamoviでデータ処理を行う大きな利点といえます。
現バージョンのjamoviには,さまざまな散布図を作成するための
scatrという拡張モジュールが標準でインストールされており,このモジュールをオンにすると探索ツールに「Scatterplot(散布図)」と「Pareto Chart(パレート図)」というメニュー項目が追加されます。これらの項目については,本書では省略します。↩︎この他に結果変数などもありますが,これらは分析によって自動的に作成されるもので,基本的に編集できません。そのため,ここの説明には含めません。↩︎
この尺度は,この練習用に作成した架空のものです。↩︎
ここでとりあげる3つの処理のうち,最初の2つについてはjamoviの分析ツールを使用して行うこともできます。↩︎
各質問文に対し「あてはまらない」,「どちらでもない」,「あてはまる」など,複数の段階で回答させて数量化する方法↩︎
尺度得点に平均値を用いる場合には,「MEAN」関数を使用します。これらの関数の詳細については付録の関数一覧を参照してください。↩︎
平均値を算出する関数には「MEAN」と「VMEAN」の2つがありますが,「MEAN」は複数の変数値の平均値を「各対象者ごと」に計算するのに対し,「VMEAN」は1つの変数値について「対象者全体」での平均値を算出する点が異なります。↩︎